Prettier CLI 深度性能剖析

本页面由 PageTurner AI 翻译(测试版)。未经项目官方认可。 发现错误? 报告问题 →
大家好,我是 Fabio,受 Prettier 团队委托来优化其命令行界面(CLI)的执行速度。本文将带您探索我发现的关键优化点、整个分析过程、新旧 CLI 的惊艳性能对比数据,以及未来潜在的优化方向。
安装方式
新版 Prettier CLI(开发中)已正式发布,您现在即可安装:
npm install prettier@next
该版本基本保持向后兼容:
prettier . --check # Like before, but faster
若遇到问题,可通过环境变量临时切换回旧版 CLI:
PRETTIER_LEGACY_CLI=1 prettier . --check
您也可通过 npx 试用(但 npx 本身执行较慢):
npx prettier@next . --check
我们的目标是实现接近 100% 的向后兼容性,最终将其整合进 prettier 包的稳定版本,全面替代现有 CLI。
架构概览
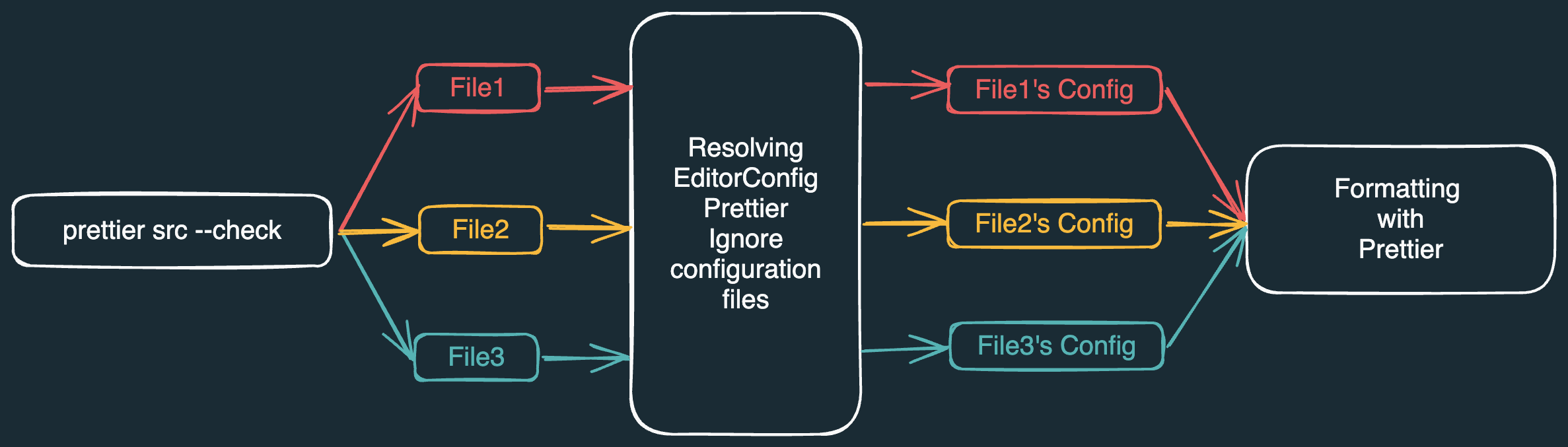
Prettier CLI 的工作流程大致如上图所示:
-
选定待执行操作(如检查文件格式是否符合规范)
-
实际定位需要执行操作的目标文件
-
解析
.gitignore和.prettierignore文件以过滤应忽略的文件 -
解析
.editorconfig文件,获取 EditorConfig 相关的格式配置 -
解析
.prettierrc等约 10 种配置文件,获取 Prettier 专属格式规则 -
逐文件校验其内容是否符合对应格式配置
-
最终将处理结果输出至终端
纵观 CLI 整体架构后,我认为主要有三点关键发现:
-
工作量与目标文件数量成正比。但由于两次 CLI 执行间多数文件通常保持不变(例如大型代码库的提交通常仅涉及部分文件),若能复用上次执行结果,即可跳过当前大部分处理流程
-
配置文件解析可能成为性能瓶颈:代码库可能包含数千文件夹,每个文件夹都可能存在配置文件。例如发现 10 个不同
.editorconfig文件时,每个文件都会为特定通配模式定义规则,需逐文件合并配置。但实践中,即使仓库包含数千文件夹,通常也仅存在少数.editorconfig文件,因此实际开销应可控 -
这个结论看似浅显却至关重要:若程序执行的都是必要操作,且每步操作都高效完成,则整体必然高效。因此我们核心策略是最大限度跳过非必要操作,并对必需操作进行极致优化
基于这些发现,我决定从零重写 Prettier CLI——相比后期修补,在初始设计时就贯穿性能意识往往更易实现质的飞跃。
在本文中,我将使用 Babel 的 monorepo 进行性能测量,这能提供良好的基准参考,让您了解在实际较大规模单体仓库中的改进效果。
快速查找文件
首先我们需要找到目标文件。Prettier 当前的 CLI 使用 fast-glob 实现此功能,其使用代码类似这样:
import fastGlob from "fast-glob";
const files = await fastGlob("packages/**/*.{js,cjs,mjs}", {
ignore: ["**/.git", "**/.sl", "**/.svn", "**/.hg", "**/node_modules"],
absolute: true,
dot: true,
followSymbolicLinks: false,
onlyFiles: true,
unique: true,
});
在 Babel 的 monorepo 上运行该代码,约需 220 毫秒查找 17,000 个匹配通配模式的文件(总共找到约 30,000 个文件)。考虑到 Babel monorepo 还包含 13,000 多个文件夹,这个速度似乎相当不错。
通过快速性能分析发现,大量时间消耗在检查找到的文件是否匹配 "ignore" 通配模式上,这些模式在内部被转换为正则表达式并逐一匹配。我尝试将通配模式合并为单个模式:"**/{.git,.sl,.svn,.hg,node_modules}",但由于内部机制它又被拆分,因此未产生效果。
完全注释掉 ignore 通配模式后,查找几乎相同的文件(因为实际被忽略的文件极少)仅需约 180 毫秒,时间减少约 20%。这说明若能以更快方式匹配这些通配模式,就能进一步降低耗时。
这里值得提到 fast-glob 的精妙优化:当通配模式形如 packages/**/*.{js,cjs,mjs} 时,它能识别开头是静态路径,实际只需在 packages 文件夹内搜索 **/*.{js,cjs.mjs}。若其他文件夹存在大量无关文件,此优化效果显著——这些文件根本不会被扫描。
这启发了我:ignore 通配模式本质相同,但静态部分在末尾而非开头。因此我开发了新的文件查找库,也能利用末尾静态的通配模式。等效代码如下:
import readdir from "tiny-readdir-glob";
const { files } = await readdir("packages/**/*.{js,cjs,mjs}", {
ignore: "**/{.git,.sl,.svn,.hg,node_modules}",
followSymlinks: false,
});
新方法仅需约 130 毫秒即可找到相同文件。为测试 ignore 通配模式的开销而将其注释后,耗时几乎不变,说明在此场景下其开销已优化到难以测量的程度。
速度提升超乎预期,原因如下:
-
除 ignore 通配模式外,主通配模式
**/*.{js,cjs,mjs}部分也获得了优化 -
通配模式需匹配文件相对于搜索根目录的路径,通常需要多次调用
path.relative。但当通配模式为**/.git时,是否计算相对路径并不影响结果——我们只需检查路径末尾。因此我完全跳过了这些path.relative调用 -
两个库内部都使用 Node.js 的
fs.readdirAPI 扫描目录,它返回文件名而非我们需要的绝对路径。通过手动拼接父路径和文件名(使用路径分隔符)而非调用path.join,可进一步加速
此外,这个新库的体积缩小了约 90%,约 65KB 的压缩代码不再需要,这显著提升了整个 CLI 的启动速度。在比 Babel 小得多的仓库中,新 CLI 可能已在旧 CLI 刚完成解析 fast-glob 时,就完成了所有目标文件的查找。
重写 CLI 的文件查找模块看似有些反应过度——毕竟直接提速效果有限——但重构的核心动机其实另有玄机。虽然初始文件查找耗时不足半秒,但关键在于整个 CLI 流程不仅需要定位待格式化文件,还需查找各类配置文件。而获取完整的目录结构信息(包括未匹配通配模式的文件/文件夹),将成为后续优化节省数秒时间的关键筹码。tiny-readdir-glob 能以近乎零成本提供这些元数据,单凭这点就值得专门为其重写实现。
本节值得关注的要点总结:
-
尽可能为 Prettier 指定文件扩展名,例如使用
packages/**/*.{js,cjs,mjs}这类 glob。若改用packages/**/*或仅packages,将额外处理 1.3 万个文件,后续丢弃这些文件的代价更高。 -
即使面对已优化的库,只要投入时间深挖,总能发现可优化点或特殊性能场景。
-
需关注哪些信息被丢弃或重构成本较高。本例中 glob 库本就需要掌握文件/文件夹信息,将其暴露给调用方几乎零成本地解锁了额外性能空间。
进一步加速的猜想方向:
- 当前瓶颈可能在于 Node.js 的
fs.promises.readdir性能,或为每个文件夹创建 Promise 的开销。值得探索回调式 API 及 Node.js 自身的优化空间。
高速解析配置
这可能是新 CLI 最关键的优化:用最高效方式查找配置文件,确保每个文件夹的配置检查仅发生一次,且每个配置文件只解析一次。
旧版 CLI 的核心问题是按文件路径而非文件夹路径缓存配置。例如 Babel 的 monorepo 有约 1.7 万个待格式化文件,但整个仓库仅 1 个 .editorconfig 文件——本应只解析一次的文件却被解析约 1.7 万次!更严重的是,若这些文件同属一个文件夹,该文件夹会被重复检查是否含 .editorconfig 文件约 1.7 万次。实际上,待格式化文件的文件夹嵌套越深,CLI 整体越慢。
我们通过两步解决此问题:
-
改为按文件夹路径缓存配置,彻底消除文件数量与嵌套深度的影响。
-
不再逐一向文件夹查询约 15 种支持的配置文件——得益于上一阶段获取的仓库完整文件树,我们直接通过内存查找实现。这在小型仓库差异不大,但对 Babel 这类含约 1.3 万个文件夹的仓库,13k × 15 次文件系统检查的累积开销极其可观。
接下来我们深入分析每种配置类型的解析机制。
解析 EditorConfig 配置
基于前一步骤已解析仓库中所有.editorconfig文件的假设,并且我们能在常数时间内获取任何目标文件的相关配置,现在我们需要针对每个目标文件将这些配置合并成一个单一的配置对象。
这个想法立刻遇到了阻碍,因为editorconfig包并未提供相关合并函数。最接近的是parseFromFiles函数(已被弃用),它似乎能实现需求,但要求以字符串形式传入配置——这意味着每次调用都会重新解析文件,而这正是我们想要避免的重复工作。
因此我们为Prettier重写了该包。tiny-editorconfig提供了我们需要的resolve函数,并将配置文件查找逻辑交由调用方实现——这正符合需求,因为我们需要自定义缓存机制。
重构过程中我还重写了其底层的INI解析器,性能提升约9倍。虽然大多数仓库仅含单个.editorconfig文件,这点优化影响有限,但重写小型解析器本身充满乐趣——况且当您的仓库存在数千个.editorconfig文件时,您将切实感受到性能提升!
此外该库体积缩小约82%,删除了约50KB压缩代码,加速了整个CLI的启动过程。更关键的是,它采用了与tiny-readdir-glob相同的glob库,而当前CLI中fast-glob和editorconfig使用不同库实现——这意味着实际删除的冗余代码量更大。
以Babel的monorepo为例:此前解析耗时需数秒,现在仅需约100毫秒。
进一步加速的猜想方向:
- 多数情况下可预解析配置文件以覆盖所有潜在文件路径。例如根据glob规则,最终可能仅需保留三种配置:未匹配任何规则的默认配置、匹配
**/*.js的配置、匹配**/*.md的配置。虽然实现复杂且实际加速效果待验证,但这是未来值得探索的方向。
解析Prettier配置
对于.prettierrc等Prettier专属配置,我们同样假设已解析所有配置文件,并能快速获取任意目标文件的相关配置。
该场景与EditorConfig配置解析完全一致,因此我们采用相同策略——这次直接在CLI内部硬编码配置合并逻辑,因为单独封装成包对生态价值有限。
我认为未来需重点关注的方面:
-
Prettier支持大量配置文件格式。以Babel的monorepo为例,这导致约15万次路径查询操作——虽非重大开销但也不容忽视。若能大幅减少支持格式数量,可带来一定速度提升。
-
部分配置文件的解析器开销较高。例如
json5解析器的代码量是已知最小JSONC解析器的100倍,解析速度有时慢50倍。减少支持格式可使CLI更轻量化。 -
如果能一次性检查整个代码库中是否存在特定名称的文件(例如
.prettierrc.json5),就能将配置文件的检查次数减少一个数量级。因为如果在整个代码库中都没发现该名称的文件,就无需向 Babel 的约 1.3 万个文件夹逐一询问。我们使用的 glob 库可以免费提供所有已知文件名的列表,这是另一项宝贵信息。
解析忽略配置
最后需要解析 .gitignore 和 .prettierignore 文件,以确定哪些已发现文件需要忽略。我们假设已解析完所有相关文件,并能以常数时间为任何目标文件获取这些配置。
此处未做重大优化,主要使用 node-ignore 生成判断文件是否应忽略的函数。
有个小优化:在某些情况下跳过调用 path.relative 和 ignore 函数本身。忽略文件的匹配规则基于目标文件相对于忽略文件所在目录的相对路径。由于我们处理的所有路径都已标准化,如果目标文件的绝对路径不以某个忽略文件所在目录的绝对路径开头,说明该文件位于该忽略文件的管理范围之外,因此无需调用 node-ignore 生成的 ignore 函数。
但匹配忽略文件中 glob 规则的过程相当耗时——数千文件可能耗费数百毫秒。因为这些文件可能包含大量 glob 规则,而目标文件数量也很庞大,最坏情况下需要尝试的匹配次数近似等于规则数与文件数的乘积。
.gitignore 和 .prettierignore 文件的优势在于其收益通常大于成本:解析这些文件并执行匹配的时间,往往少于处理被忽略文件所需的时间。
进一步加速的猜想方向:
-
或许可将多数 glob 规则合并为单个复杂规则,由引擎一次性完成匹配(我们只需知道是否有任意规则匹配,无需具体匹配信息)
-
调整 glob 规则的执行顺序:先执行成本低、覆盖广的规则,平均可能减少匹配时间(不过当多数文件未被忽略时效果有限)
-
通过缓存记录文件路径的匹配结果,但感觉不依赖缓存也能大幅提速
缓存机制
至此我们已完成文件发现和配置解析,接下来是实际执行高成本的格式化操作——这正是缓存发挥作用之处。
当前 CLI 支持某种形式的缓存,但需显式启用 --cache 标志,且仅记录"已正确格式化"的文件状态,未记录"未正确格式化"的状态。这可能导致额外开销:这些未格式化文件在后续检查时会被重新格式化,而其实我们本可记住它们的状态。
我们的目标是:通过记录文件格式化状态跳过最多工作,同时生成合理大小的缓存文件,并确保缓存机制本身不引入过多开销。
新 CLI 采用了“默认启用缓存”的设计——除非你显式使用 --no-cache 标志禁用,否则缓存功能始终开启。这样默认就能让更多人享受到缓存带来的性能提升。同时,由于缓存机制已全面覆盖关键因素,理论上不会出现缓存提供错误信息的情况。当以下任一要素发生变化时,缓存或其相关部分会自动失效:Prettier 版本、所有已解析的 EditorConfig/Prettier/Ignore 配置文件及其路径、通过 CLI 标志传递的格式化选项、文件的实际内容以及文件路径。
这里的关键设计在于:我们避免让每个文件的缓存与其解析后的格式化配置形成_直接_依赖关系。因为直接依赖需要为每个目标文件合并配置文件、序列化结果对象并进行哈希计算——这种操作的开销远超预期。
新 CLI 的解决方案是:仅解析所有配置文件,然后直接对其进行序列化和哈希计算。无论后续需要格式化多少文件,此操作耗时恒定,且只需在缓存文件中记录一个哈希值即可_间接_覆盖所有配置文件。这种设计是安全的——只要配置文件路径_及_内容不变,那么与历史运行中路径相同的文件,其解析后的格式化配置必然一致。唯一潜在风险是解析依赖存在缺陷,但最坏情况下只需同步更新 Prettier 和有缺陷的依赖版本即可解决。
通过具体数据对比:当前 CLI 在无缓存状态下检查 Babel monorepo 约需 29 秒,而新 CLI 在无缓存且未并行处理时仅需 7.5 秒。启用缓存后,当前 CLI 仍需 22 秒,新 CLI 则仅需 1.3 秒——未来通过优化该时间有望再缩减一半。
若要从本文记住一个核心建议,那就是:务必保留缓存文件以最大化 CLI 速度。默认缓存路径为 ./node_modules/.cache/prettier,可通过 --cache-location <path> 标志自定义位置。再次强调:若追求极致性能,在多次运行间保留缓存文件是提速最关键的手段。
进一步加速的猜想方向:
-
优化 Node 的哈希计算性能:相同哈希在 Bun 中计算快约 3 倍,说明存在优化空间。我已向 Node 团队提交报告,但目前尚无解决该复杂问题的 PR。
-
缓存解析后的配置文件(而非仅记录哈希值),但由于这类文件通常数量极少,收益可能有限。
-
删除冗余代码或采用懒加载机制,进一步提升全缓存路径的执行效率。
格式化改进
现在,我们已抵达流程终点:确定了待格式化文件列表,接下来只需执行操作。
我尚未深入优化核心格式化函数——处理少量文件时其性能已足够理想,且 CLI 的主要瓶颈源于低效的配置解析和未复用历史工作成果。这可能是下一步重点研究方向,但初步性能分析显示其中暂无显著或易实现的优化机会。
不过,我还尝试了其他几种方法。
首先,现在支持并行格式化多个文件,这已成为默认行为,同时提供 --no-parallel 标志来禁用此功能。还可使用 --parallel-workers <int> 标志自定义工作线程数量进行微调。在我的10核电脑上,启用并行处理后检查 Babel 的 monorepo 所需时间从 ~7.5 秒降至 ~5.5 秒,提升幅度看似不大——我尚未找出扩展性未达预期的原因,后续会深入研究。但对于更大型的代码库和使用数百核的 CI 环境,该优化配合其他改进可能带来显著差异。
最后我尝试用 @wasm-fmt/biome_fmt(Biome 格式化函数编译的 WASM 版本)快速替换 Prettier 的格式化函数。在未启用并行时检查 Babel monorepo 耗时 ~3.5 秒,启用后降至 ~2.2 秒,比 Prettier 自有格式化器快约 2 倍。若 Biome 的格式化函数能编译为原生 Node 模块,性能提升可能更大。
进一步加速的猜想方向:
-
核心格式化逻辑目前仍有约 2 倍优化空间,但改进工作可能较为复杂。不过可以肯定,这方面确实存在提升余地。
-
虽然
--parallel默认启用,但在处理少量文件时,过多工作线程可能导致任务碎片化,反而轻微拖慢速度。未来可通过启发式算法动态调整线程池规模解决。当前保留默认启用是因为:在轻量任务中减速可忽略,而在重量级任务中能带来显著收益。
终端输出优化
最后一步是将 CLI 执行结果输出至终端。
这部分优化空间有限,但仍有两处改进:
-
当前 CLI 在格式化大量小文件时,会频繁输出当前文件路径并立即清除(格式化完成后)。这种操作对数千文件异常耗时:
console.log同步调用阻塞主线程,且 16ms 内百次刷新毫无意义(人眼根本无法捕捉)。新版 CLI 已取消格式化中文件路径的实时输出,某些场景可节省数百毫秒。 -
最后,当前 CLI 可能调用数千次
console.log(具体取决于待格式化的文件数量),而新版 CLI 采用日志批处理,最终仅执行单次console.log输出——这在特定情况下也能显著提速。
该领域主要优化方向或是设计更生动的视觉反馈(分散用户对耗时的注意力),因为感知性能有时比实际性能更重要——但需确保不增加计算机负载。
性能实测
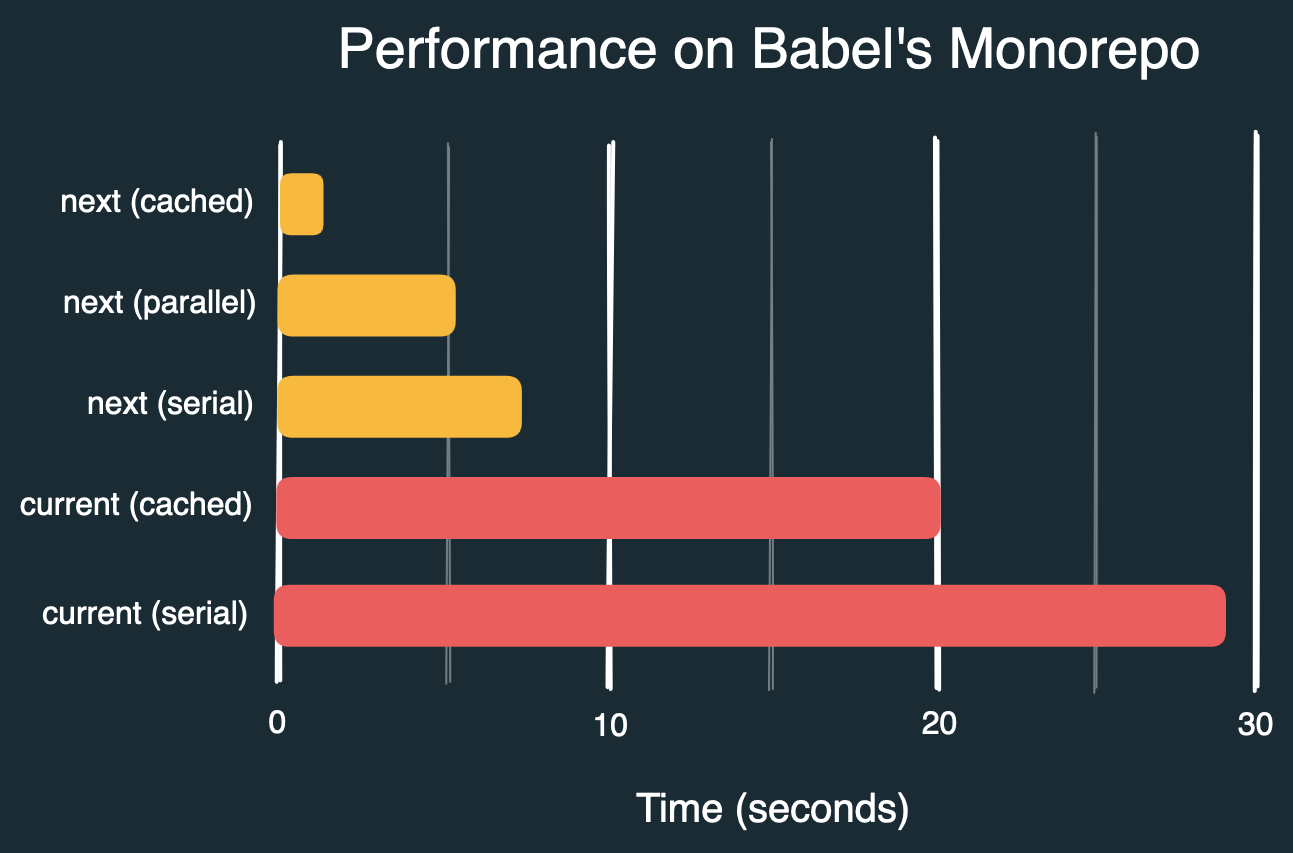
结束前展示实测数据:在 Babel monorepo 中检查文件(全部已格式化但含9个错误文件),对比不同参数下新旧 CLI 表现:
prettier packages --check # 29s
prettier packages --check --cache # 20s
prettier@next packages --check --no-cache --no-parallel # 7.3s
prettier@next packages --check --no-cache # 5.5s
prettier@next packages --check # 1.3s
在缓存文件可复用的情况下,相同命令的执行时间从约29秒缩短至约1.3秒,实现了约22倍的加速。未来我们有望进一步接近50倍加速。
若缓存文件不可用、主动关闭缓存功能或首次执行时,在我的设备上通过并行处理可将时间从约29秒降至约5.5秒,实现约5倍加速,提升幅度依然显著。
需要再次强调的是,这些优化成果均未改动 Prettier 核心的 format 格式化函数。
与 Biome 的对比结果
将我们的数据与当前 Rust 格式化器性能标杆 Biome 进行对比颇具参考价值:
biome format packages
# Diagnostics not shown: 25938.
# Compared 28703 file(s) in 869ms
# Skipped 4770 file(s)
此处 Biome 比我们的 CLI 多检测了约1.1万个文件,因为他们尚未实现 .gitignore 和/或 .prettierignore 的解析逻辑。两者在行为模式上可能还存在其他显著差异。
我们通过临时修改 CLI 禁用忽略文件功能,以更贴近 Biome 的行为模式后得到如下数据:
prettier@next packages --check --no-cache # 15s
由于工具行为存在差异,此对比需谨慎看待。但 Biome 处理海量文件的格式化检测速度确实令人惊叹——这种速度级别可能需要依赖缓存机制才能匹敌。
我们正在探索多种技术路径,力求为用户带来质的性能飞跃。
结语
新版 CLI 仍在持续完善中,诚邀您立即安装体验!
欢迎通过推特 @PrettierCode 或直接 @fabiospampinato 分享您的加速实测数据,特别是关于进一步优化建议的思考。