Prettiers CLI: En djupdykning i prestanda

Denna sida har översatts av PageTurner AI (beta). Inte officiellt godkänd av projektet. Hittade du ett fel? Rapportera problem →
Hej, jag är Fabio och har anlitats av Prettier-teamet för att snabba upp Prettiers kommandoradsgränssnitt (CLI). I detta inlägg ska vi titta på de optimeringar jag upptäckt, processen som ledde till dem, några spännande siffror som jämför den nuvarande CLI:n med den nya, samt förslag på vad som kan optimeras härnäst.
Installation
Den nya CLI:n för Prettier som fortfarande är under utveckling har precis släppts, och du kan installera den nu:
npm install prettier@next
Den bör vara till stor del bakåtkompatibel:
prettier . --check # Like before, but faster
Om du stöter på problem kan du temporärt använda den gamla CLI:n via en miljövariabel:
PRETTIER_LEGACY_CLI=1 prettier . --check
Du kan också testa den via npx, fast npx i sig är ganska långsamt:
npx prettier@next . --check
Målet är att göra den nästan ~100% bakåtkompatibel och sedan leverera den i en framtida stabil utgåva av prettier-paketet, där den ersätter den nuvarande CLI:n.
Översikt
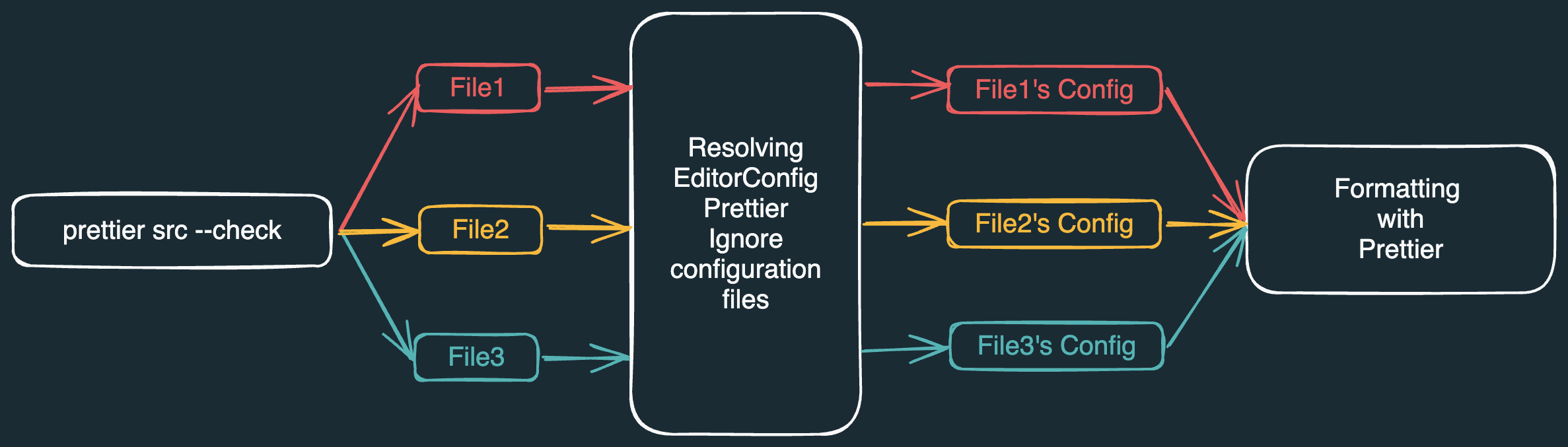
Prettiers CLI fungerar ungefär som i diagrammet ovan:
-
Det finns någon åtgärd vi vill utföra på filer, till exempel kontrollera om de är korrekt formaterade.
-
Vi måste faktiskt hitta alla filer som denna åtgärd ska utföras på.
-
Vi måste hantera
.gitignoreoch.prettierignore-filer för att avgöra om vissa filer ska ignoreras. -
Vi måste hantera
.editorconfig-filer för EditorConfig-specifika formateringsinställningar. -
Vi måste hantera
.prettierrc-filer och ~10 till för Prettier-specifika formateringsinställningar. -
Vi måste kontrollera om varje fil matchar sina formateringsinställningar.
-
Slutligen måste vi presentera någon form av resultat i terminalen.
Efter denna översikt över CLI:ns arkitektur ser jag främst tre observationer:
-
Arbetsmängden ökar med antalet målfiler, men de flesta filer ändras inte mellan CLI-körningar. I ett tillräckligt stort repo berör vanligtvis varje commit bara en bråkdel av filerna. Om vi kunde minnas arbetet från föregående körning, kunde mycket av arbetet i nuvarande körning hoppas över.
-
Det kan finnas ett enormt antal konfigurationsfiler att hantera eftersom vårt repo kan ha tusentals mappar, var och en med potentiella konfigurationsfiler. Om vi hittar 10 olika
.editorconfig-filer kan var och en definiera inställningar för filer som matchar specifika globs, vilket måste kombineras för varje målfil. Men i praktiken innehåller de flesta repos bara ett fåtal.editorconfig-filer även med många mappar, så detta borde inte bli så kostsamt. -
Detta är ingen särskilt djupgående observation, men om allt ett program gör är nödvändigt och utförs effektivt, måste programmet självt köras effektivt. Därför kommer vi i huvudsak försöka hoppa över onödigt arbete så mycket som möjligt, och det vi inte kan hoppa över kommer vi försöka göra effektivt.
Baserat på dessa observationer började jag skriva en helt ny CLI för Prettier från grunden, eftersom det ofta är enklare att skriva om saker med prestanda i åtanke från början än att lappa ihop dem efteråt.
Jag kommer använda Babels monorepo för mätningar i detta inlägg, eftersom det ger ett bra riktmärke och ger en uppfattning om förbättringarna i praktiken för ett verkligt, ganska stort monorepo.
Hitta filer snabbt
Först måste vi hitta våra målfiler. Prettiers nuvarande CLI använder fast-glob för detta, och koden för att använda det kan se ut så här:
import fastGlob from "fast-glob";
const files = await fastGlob("packages/**/*.{js,cjs,mjs}", {
ignore: ["**/.git", "**/.sl", "**/.svn", "**/.hg", "**/node_modules"],
absolute: true,
dot: true,
followSymbolicLinks: false,
onlyFiles: true,
unique: true,
});
Om vi kör det på Babels monorepo ser vi att det tar ungefär ~220ms att hitta ~17k filer som matchar våra globs, av ~30k totalt hittade filer, vilket verkar ganska bra med tanke på att Babels monorepo också innehåller över 13k mappar.
Med en snabb profilering kan vi se att en betydande mängd tid spenderas på att kontrollera om de hittade filerna matchar någon av våra "ignore"-globs, som verkar konverteras internt till regex och matchas en efter en. Så jag försökte slå ihop globsen till en enda: "**/{.git,.sl,.svn,.hg,node_modules}", men den verkar delas upp internt igen av någon anledning, så det förändrade ingenting.
Genom att helt kommentera bort våra ignore-globs kan vi hitta i stort sett samma filer, eftersom nästan ingen av dem faktiskt ignorerades, på bara cirka ~180ms, vilket är ~20% mindre tid. Så om vi kunde matcha dessa globs på ett annat, snabbare sätt, skulle vi kunna minska tiden lite.
Det här är förmodligen ett bra tillfälle att nämna att fast-glob gör en ganska cool optimering. Om vårt globmönster ser ut så här: packages/**/*.{js,cjs,mjs}, kan den upptäcka att början är helt statisk. Det vi egentligen ber den att göra är att söka efter **/*.{js,cjs.mjs} enbart i mappen packages. Den här optimeringen kan vara betydande om det finns många filer i andra mappar vi inte bryr oss om, eftersom de aldrig kommer att skannas.
Det fick mig att tänka: våra ignore-globbar är i princip desamma, men den statiska delen är i slutet istället för i början. Så jag skrev ett annat bibliotek för att hitta filer med en glob som också kan dra nytta av globbar med ett statiskt slut. Motsvarande kod för att hitta filer med det skulle se ut så här:
import readdir from "tiny-readdir-glob";
const { files } = await readdir("packages/**/*.{js,cjs,mjs}", {
ignore: "**/{.git,.sl,.svn,.hg,node_modules}",
followSymlinks: false,
});
Och den hittar samma filer på bara cirka ~130 ms. Genom att kommentera bort ignore-globen, bara för att kolla hur mycket överhögg det tillför, verkar det ta ungefär lika lång tid, så att den blev tillräckligt optimerad för att det ska vara svårt att mäta dess kostnad i detta scenario.
Hastigheten ökade mer än förväntat av flera skäl:
-
Förutom ignore-globen optimerades även
**/*.{js,cjs,mjs}-delen av huvudgloben. -
Globs matchas mot filens relativa sökväg från rotmappen, vilket normalt kräver många
path.relative-anrop. Men för globs som**/.gitspelar relativ sökväg ingen roll – vi kan kolla direkt på strängslutet och hoppa över dessapath.relative-anrop. -
Båda biblioteken använder Nodes
fs.readdirför att skanna mappar. Istället för att anropapath.joinför att skapa absoluta sökvägar gör vi detta manuellt genom att kombinera föräldersökväg och filnamn med sökvägsseparatorn, vilket ger ytterligare prestandavinster.
Dessutom är detta nya bibliotek ungefär 90 % mindre – cirka 65 kb minifierad kod behövs inte längre, vilket snabbar upp uppstarten för hela CLI:n. I mycket mindre repos än Babels kan den nya CLI:n hitta alla målfiler innan den gamla ens hunnit tolka fast-glob.
Att skriva om denna del av CLI:n kan verka överdrivet för den hastighetsökning vi fick, men huvudorsaken till omskrivningen är faktiskt en annan. Det kan tyckas som att inget vi gör här skulle kunna snabba upp CLI:n med flera sekunder, eftersom filletandet tar mindre än en halvsekund från början. Men den avgörande punkten är att vi för hela CLI:n inte bara måste hitta filer att formatera – vi måste också hitta konfigurationsfiler. Att känna till varje enskild fil och mapp som hittats (även om de inte matchade våra globs) är värdefull information som senare sparar flera sekunder. tiny-readdir-glob kan ge oss denna information nästan gratis, vilket gjort det värt att utveckla biblioteket enbart för detta.
Sammanfattning av intressanta insikter från detta avsnitt:
-
Ange alltid filändelser för Prettier när möjligt, t.ex. med glob som
packages/**/*.{js,cjs,mjs}. Hade du använtpackages/**/*eller barapackagesi detta scenario skulle 13k extra filer behöva bearbetas, vilket gör det dyrare för Prettier att förkasta dem senare. -
Det finns alltid fler optimeringar eller specialfall att utforska för prestanda, även i redan optimerade bibliotek – om man har tid att undersöka.
-
Fundera över vilken information som kastas bort eller blir kostsam att återskapa. Här måste glob-biblioteket känna till hittade filer/mappar för sitt arbete – att exponera denna information ger fri prestandavinst i vissa fall.
Gissningar om hur man kan påskynda detta ytterligare:
- Flaskhalsen verkar vara prestandan hos
fs.promises.readdiri Node och/eller kostnaden för att skapa Promises per mapp. Det kan vara värt att utforska callback-versionen av detta API samt optimeringar i Node självt.
Snabb konfigurationslösning
Denna optimering är troligtvis den mest effektfulla i nya CLI:n och handlar om att: 1) hitta konfigurationsfiler extremt snabbt, 2) endast kontrollera varje mapp en gång för konfigurationsfiler, och 3) endast tolka hittade konfigurationsfiler en gång.
Ett stort problem i nuvarande CLI är cachelagring av konfigurationer per filsökväg istället för mappsökväg. Exempelvis har Babels monorepo ~17k filer men endast 1 .editorconfig-fil – den borde tolkas en gång men tolkades ~17k gånger. Dessutom: om alla ~17k filer ligger i en mapp, frågades den mappen ~17k gånger om den innehöll .editorconfig. Djupare nästlade filer gjorde alltså CLI:n exponentiellt långsammare.
Problemet löstes i två steg:
-
Konfigurationer cachelagras nu per mappsökväg – oberoende av antal filer eller mappdjup.
-
Mappar frågas nu i princip noll gånger om de innehåller de ~15 konfigurationsfiltyperna, eftersom vi från filletandet redan känner till alla filer i repot. En enkel uppslagning är mycket snabbare än filsystemanrop. I små repos spelar detta mindre roll, men i Babels med ~13k mappar skulle 13k × 15 filsystemkontroller
adderasmultipliceras upp alldeles för fort.
Låt oss nu granska hur varje specifik konfigurationstyp hanteras:
Lösa EditorConfig-konfigurationer
Om vi utgår från föregående steg där vi tolkat alla .editorconfig-filer i repot och kan hämta relevanta för valfri målfil i konstant tid, vill vi nu i princip slå samman dem till ett enda konfigurationsobjekt per målfil.
Denna idé går genast i stöpet eftersom editorconfig-paketet inte tillhandahåller en funktion för detta. Den närmaste funktionen verkar vara parseFromFiles, som förutom att vara föråldrad verkar göra vad vi vill. Men den kräver konfigurationer som strängar, så den kommer förmodligen tolka dem själv vid varje anrop - precis det vi ville undvika från början. Vi vill bara tolka dessa en enda gång.
Därför skrevs paketet om för Prettiers behov. tiny-editorconfig tillhandahåller exakt den resolve-funktion vi behöver och lämnar logiken för att hitta konfigurationsfiler till oss, vilket är vad vi vill eftersom vi behöver cacha dessa filer på ett anpassat sätt.
Medan jag ändå höll på skrev jag också om INI-tolkningsbiblioteket bakom det, och det verkar vara ~9x snabbare. Det borde inte spela så stor roll eftersom de flesta repon bara har en .editorconfig-fil, men jag tycker om att skriva sådana småtolkningsbibliotek. Och om du råkar ha tusentals .editorconfig-filer i ditt repo kommer du märka extra prestandavinst!
Dessutom är detta nya bibliotek ~82% mindre - ~50kb minifierad kod togs bort, vilket snabbar upp starttiden för hela CLI:n. Det använder också samma glob-bibliotek som tiny-readdir-glob använder, medan den nuvarande CLI:n använder olika bibliotek för fast-glob och editorconfig, så faktiskt ännu mer kod effektiviserades bort.
Tidigare tog det flera sekunder att matcha dessa filer för Babels monorepo - nu tar det ungefär ~100ms.
Gissningar om hur man kan påskynda detta ytterligare:
- I vissa (de flesta?) fall borde det gå att förberäkna dessa konfigurationsfiler för alla möjliga filsökvägar vi kan stöta på. Beroende på globbarna i dem kan vi till exempel komma fram till maximalt 3 möjliga konfigurationer: en för filer som inte matchar några globbar, en för filer som matchar globben
**/*.js, och en för filer som matchar**/*.md. Det är lite komplicerat att implementera dock, och oklart vilken prestandavinst det ger i praktiken - men något att fundera på framöver.
Hantering av Prettier-konfigurationer
För Prettier-specifika konfigurationer som .prettierrc-filen antar vi också att vi har matchat alla hittade konfigurationsfiler och kan hämta dem i konstant tid för valfri målfil.
Det är i princip samma situation som vi hade för EditorConfig-konfigurationer, så vi gör i stort sett samma sak här. Denna gång hårdkodar vi logiken för att sammanfoga konfigurationerna i själva CLI:n, eftersom ett fristående paket för detta inte verkar ha någon praktisk nytta för ekosystemet.
De huvudsakliga aspekterna att överväga här framöver är enligt mig:
-
Ett stort antal olika konfigurationsfiler stöds. I Babels monorepo resulterar detta i ~150k uppslagningar i objektet med kända sökvägar vi skapade i första steget. Även om det inte är extremt kostsamt är det inte gratis heller. Om detta antal kunde minskas avsevärt skulle det snabba upp saker något.
-
Vissa av tolkningsbiblioteken som behövs för dessa konfigurationsfiler är relativt kostsamma.
json5-tolkaren kräver ~100x mer kod än det minsta JSONC-biblioteket (JSON med kommentarer) jag känner till för JavaScript, samtidigt som den i vissa fall är ~50x långsammare vid tolkning. Om färre format kunde stödjas skulle CLI:n bli smidigare som följd. -
Om vi kunde kontrollera bara en gång om en fil med namn som t.ex.
.prettierrc.json5fanns någonstans i repot, skulle vi kunna minska antalet kontroller för dessa konfigurationsfiler med en storleksordning. Om ingen fil med det namnet hittades i repot behöver vi inte fråga vart och ett av Babels ~13k mappar om de har den. Listan över alla kända filnamn är ytterligare värdefull information som glob-biblioteket vi använder skulle kunna ge oss gratis.
Hantering av Ignore-konfigurationer
Slutligen behöver vi hantera .gitignore och .prettierignore-filer för att förstå vilka hittade filer som ska ignoreras. Vi antar också att vi redan har löst alla hittade filer och kan hämta dem i konstant tid för vilken målfil som helst.
Jag gör inga större optimeringar här, jag ber i huvudsak bara node-ignore att skapa en funktion som vi kan anropa för att kontrollera om en fil ska ignoreras.
En liten optimering är dock att hoppa över anrop till path.relative och ignore-funktionen i vissa fall. Ignore-filer matchar ungefär den relativa sökvägen för hittade filer från mappen där ignore-filen finns. Eftersom vi vet att alla sökvägar vi hanterar är normaliserade, om en målfils absoluta sökväg inte börjar med ignore-filens absoluta mappsökväg, finns filen utanför den mapp ignore-filen hanterar. Då behöver vi inte anropa ignore-funktionen som node-ignore skapat för oss.
En betydande tid verkar ändå läggas på att matcha globs i dessa filer mot de hittade filerna - hundratals millisekunder för tusentals filer. Det kan finnas många globs i dessa filer och många filer att matcha, vilket multiplicerat ger oss antalet glob-matchningar som måste försökas i värsta fall.
Det fina med .gitignore och .prettierignore-filer är dock att de ofta lönar sig - tiden spenderad på att tolka dem och matcha filer mot dem är ofta mindre än tiden som skulle behövas för att bearbeta varje fil som de skulle ha filtrerat bort.
Gissningar om hur man kan påskynda detta ytterligare:
-
Kanske kan de flesta globs slås ihop till en enda mer komplex glob och matchas samtidigt av motorn, eftersom vi bara är intresserade av om någon glob matchar inte vilken specifik.
-
Kanske kan globs köras i en annan ordning - genom att köra enklare och bredare globs först kan vi i genomsnitt lägga mindre tid på matchning. Detta skulle dock inte göra skillnad om de flesta filer inte ignoreras.
-
Vi skulle kunna komma ihåg vilka filsökvägar som matchade med en cache, men det känns som att detta kan optimeras kraftigt utan caching också.
Caching
Nu har vi hittat alla filer och tolkat alla konfigurationer. Återstår att göra det faktiska potentiellt kostsamma arbetet att formatera varje målfil - och det är där caching kommer in.
Den nuvarande CLI:n har stöd för en form av caching, men den är opt-in (kräver explicit --cache-flagga) och kommer bara ihåg om en fil i föregående körning var korrekt formaterad, inte om den var felformaterad. Det kan orsaka onödig overhead eftersom dessa felformaterade filer skulle formateras igen för kontroll när vi kunnat komma ihåg från tidigare körning att de inte är korrekta.
Vårt mål här är att hoppa över så mycket arbete som möjligt genom att komma ihåg om en fil var formaterad eller inte, samtidigt som vi genererar rimligt små cachefiler utan att introducera för mycket overhead med cachningsmekanismen.
Den nya CLI:n har istället cacheminne som standard, så caching är alltid aktiverat om du inte explicit stänger av det med flaggan --no-cache. På så sätt når fördelarna många fler användare automatiskt. Cachen är nu aktiverad som standard eftersom den tar hänsyn till allt, så det borde inte vara realistiskt att cachen ger CLI:n felaktig information. Om något av följande ändras, ogiltigförklaras cachen automatiskt (helt eller delvis): Prettiers version, alla löst EditorConfig/Prettier/Ignore-konfigurationsfiler och deras sökvägar, formateringsalternativ angivna via CLI-flaggor, innehållet i varje fil samt filens sökväg.
Knepet här är att vi inte vill att cachen för varje fil ska vara direkt beroende av dess löst formateringskonfiguration. Det skulle kräva att vi slår ihop konfigurationsfiler för varje målfil, serialiserar det resulterande objektet och hashar det – vilket kan bli betydligt dyrare än önskat.
Istället parsar den nya CLI:n alla hittade konfigurationsfiler, serialiserar och hashar dem. Detta tar konstant tid oavsett hur många filer vi sen ska formatera, och kräver bara en enda hash i cachefilen för att indirekt hantera konfigurationsfiler. Det är säkert eftersom en fil med samma sökväg som tidigare alltid får samma formateringskonfiguration om konfigurationsfilernas sökvägar och innehåll är oförändrade. Enda risken är buggar i beroenden som används för att tolka filerna, men i värsta fall kan Prettiers egen version ökas tillsammans med det buggiga beroendet.
För att ge siffror: den nuvarande CLI:n kontrollerar Babels monorepo utan cache på ~29 sekunder. Den nya CLI:n behöver ~7,5s för samma sak utan cache och utan parallellisering. Med aktiverad cachefil behöver den nuvarande CLI:n fortfarande ~22 sekunder, medan den nya klarar det på ~1,3 sekunder. Denna tid kan förmodligen halveras med framtida optimeringar.
Om det finns något att minnas från detta inlägg är det: vill du att CLI:n ska gå så snabbt som möjligt måste du bevara cachefilen. Cachefilen lagras som standard under ./node_modules/.cache/prettier, och dess plats kan ändras med flaggan --cache-location <path>. Jag upprepar: om prestanda är viktigt i ditt scenario är det absolut viktigaste du kan göra för att snabba upp processen att bevara cachefilen mellan körningar.
Gissningar om hur man kan påskynda detta ytterligare:
-
En möjlig optimering är att snabba upp hashing i Node. Samma hashberäkningar verkar vara ~3x snabbare i Bun, så det finns säkert utrymme för förbättring. Jag har rapporterat detta till Node, men ingen PR har lämnats in än – det verkar komplicerat.
-
De tolkade konfigurationsfilerna skulle kunna cachas direkt, inte bara deras hash. Men eftersom det vanligtvis bara är ett fåtal så spelar det förmodligen inte så stor roll.
-
Mer kod skulle kunna tas bort eller laddas lazy, vilket skulle snabba upp den fullt cachade vägen ytterligare.
Formatering
Vi har nu nästan nått slutet av pipelinen. Vi vet vilka filer som ska formateras, och nu gäller det bara att göra det.
Jag har inte undersökt optimering av själva formateringsfunktionen särskilt noggrant, eftersom den redan verkar rimligt snabb för få filer. Den största flaskhalsen i CLI:n verkade komma från ineffektiv konfigurationslösning och att tidigare arbete inte återanvändes. Men det kan vara nästa stora optimeringsområde. Kanske finns inga större och/eller enkla optimeringar där – vid en snabb profilering såg jag inga uppenbara.
Jag har dock testat några andra saker.
För det första kan flera filer formateras parallellt – detta är nu standard och en --no-parallel-flagga finns för att avaktivera funktionen. Flaggan --parallel-workers <int> kan också användas för att manuellt ställa in antalet arbetsprocesser. På min 10-kärniga dator minskar tiden för att kontrollera Babels monorepo från ~7.5s till ~5.5s med parallellisering, vilket inte verkar särskilt imponerande. Jag är osäker på varför skalningen inte är bättre och hoppas undersöka detta närmare. För större repos och CI-maskiner med hundratals kärnor kan skillnaden bli betydligt större, framför allt kombinerat med andra optimeringar.
Slutligen testade jag att snabbt ersätta Prettiers formateringsfunktion med @wasm-fmt/biome_fmt – Biomes formateringsfunktion kompilerad till WASM. Då såg jag ~3.5s för att kontrollera Babels monorepo utan parallellisering och ~2.2s med parallellisering. Ungefär dubbelt så bra siffror jämfört med Prettiers egen formaterare. Förbättringen skulle potentiellt kunna bli ännu större om Biomes formateringsfunktion kompilerades till ett inbyggt Node-modul.
Gissningar om hur man kan påskynda detta ytterligare:
-
Jag har inte arbetat mycket med kärnformateringen, som verkar minst 2x långsammare än optimalt. Arbetet för att nå dit kan bli omfattande, men det finns definitivt utrymme för förbättringar.
-
Flaggan
--parallelär aktiverad som standard men har en mindre nackdel: om du har få filer att formatera men många kärnor kan varje kärna få för få filer, vilket faktiskt kan sakta ner processen något. Detta kan troligtvis lösas med dynamisk poolstorlek baserat på heuristik. Den är aktiverad som standard eftersom den bara saktar ner i scenarier som ändå är snabba, samtidigt som den ger betydande förbättringar i annars långsamma situationer.
Utmatning till terminalen
Slutligen är det sista steget att mata ut resultatet av kommandot som CLI:n ombads att köra till terminalen.
Det fanns inte mycket att optimera här, men några möjligheter fanns:
-
I vissa fall (t.ex. vid formatering av många små filer) matade den nuvarande CLI:n snabbt ut aktuell filväg, för att sedan radera utmatningen en millisekund senare. Att göra detta för tusentals filer är förvånansvärt kostsamt eftersom
console.log-anrop är synkrona och blockerar huvudtråden. Dessutom är det meningslöst om vi gör det 100 gånger på 16ms – skärmen uppdateras bara 1-2 gånger under den tiden. Den nya CLI:n loggar inte filer under formatering, vilket sparar hundratals millisekunder i vissa fall. -
Den nuvarande CLI:n kan anropa
console.logtusentals gånger, medan den nya batchar loggar och endast utför ett endaconsole.log-anrop i slutet, vilket också kan vara förvånansvärt snabbare.
Den största förbättringsmöjligheten här är att skapa något visuellt intressant som engagerar användaren, eftersom upplevd prestanda kan vara viktigare än faktisk prestanda – men utan att belasta datorn i samma utsträckning.
Resultat
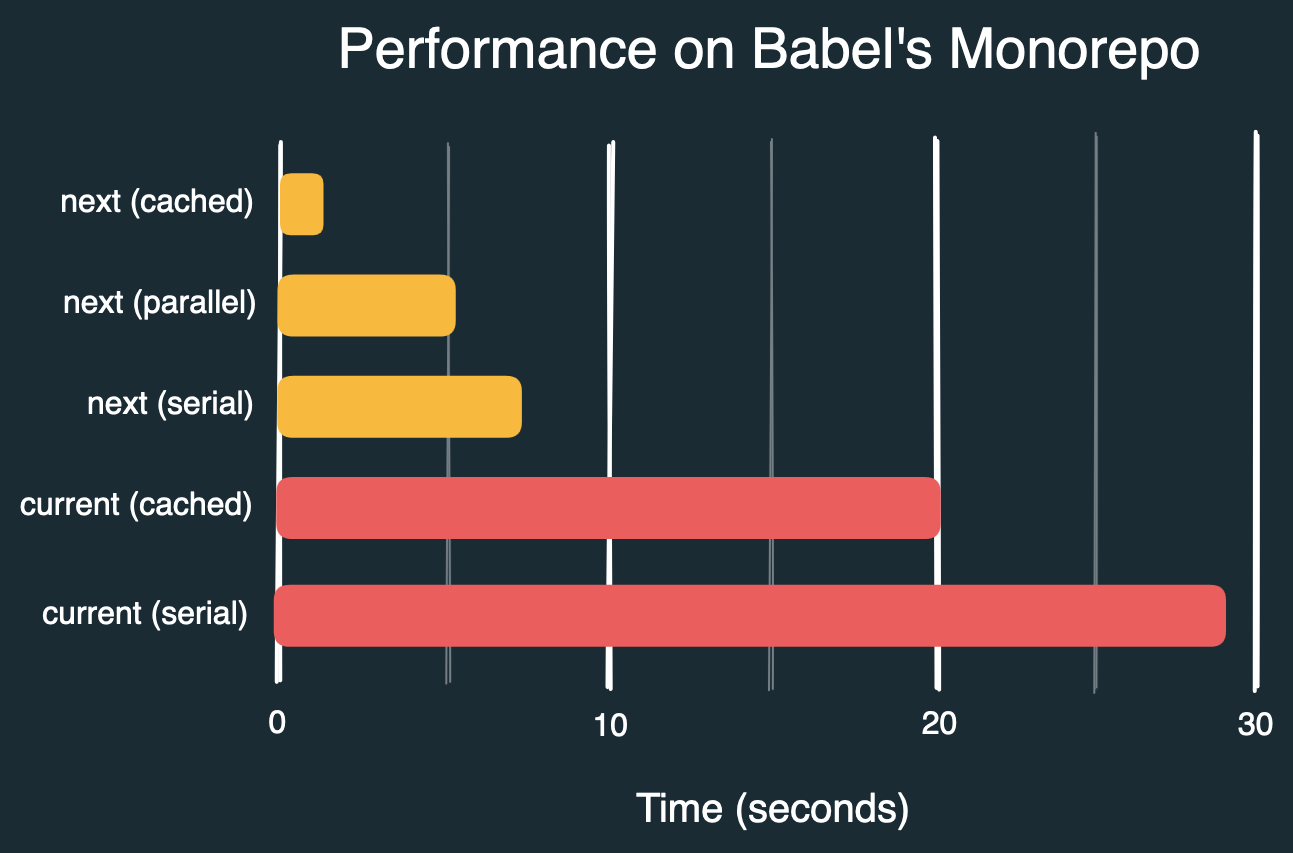
Innan vi avslutar: här är siffror jag får när jag kontrollerar filer i Babels monorepo med alla filer formaterade (men 9 felande filer), olika flaggor, och både nuvarande och ny CLI:
prettier packages --check # 29s
prettier packages --check --cache # 20s
prettier@next packages --check --no-cache --no-parallel # 7.3s
prettier@next packages --check --no-cache # 5.5s
prettier@next packages --check # 1.3s
Som standard går tiden för samma kommando från ~29 s till ~1,3 s, vilket ger en ~22x hastighetsökning. Detta kräver att cachefilen bevaras mellan körningar. Vi kan förmodligen komma mycket närmare en 50x hastighetsökning i framtiden.
Om cachefilen inte bevaras, eller om du explicit stänger av cachning, eller om detta är första körningen, så går tiden från ~29 s till ~5,5 s med parallellisering på min dator – en ~5x hastighetsökning som fortfarande är betydande.
Värt att notera igen: denna förbättring uppnås utan ändringar i Prettiers format-funktion.
Resultat jämfört med Biome
Det är intressant att jämföra våra siffror med Biome, den ledande Rust-formateraren och förmodliga prestandamästaren:
biome format packages
# Diagnostics not shown: 25938.
# Compared 28703 file(s) in 869ms
# Skipped 4770 file(s)
Här kontrollerar Biome formateringen för ~11k fler filer jämfört med vår CLI, eftersom de ännu inte verkar implementera .gitignore och/eller .prettierignore. Det kan även finnas andra beteendeskillnader.
Genom att manuellt modifiera vår CLI för att inaktivera stöd för ignore-filer (för att bättre efterlikna Biomes beteende) får vi följande siffra:
prettier@next packages --check --no-cache # 15s
Jämförelsen bör tas med en nypa salt eftersom verktygen inte gör exakt samma sak, men det är intressant att se hur snabbt Biome kan kontrollera många filer – en hastighet vi förmodligen behöver cache för att matcha.
Olika tillvägagångssätt för att dramatiskt öka hastigheten för användare.
Avslutning
Den nya CLI:n är fortfarande under utveckling, men vi uppmuntrar dig att prova den! Du kan installera den redan idag.
Det vore spännande att se vilken hastighetsökning den nya CLI:n ger dig. Dela gärna resultatet med @PrettierCode eller direkt till @fabiospampinato, särskilt om du har idéer till ytterligare optimeringar.