L'interface en ligne de commande de Prettier : une analyse approfondie des performances

Cette page a été traduite par PageTurner AI (bêta). Non approuvée officiellement par le projet. Vous avez trouvé une erreur ? Signaler un problème →
Bonjour, je suis Fabio et l'équipe Prettier m'a missionné pour accélérer l'interface en ligne de commande (CLI) de Prettier. Dans cet article, nous allons examiner les optimisations que j'ai découvertes, le processus qui a mené à leur identification, des chiffres prometteurs comparant l'ancienne et la nouvelle CLI, ainsi que quelques hypothèses sur les prochaines pistes d'optimisation possibles.
Installation
La nouvelle CLI en cours de développement pour Prettier vient d'être publiée, et vous pouvez dès à présent l'installer :
npm install prettier@next
Elle devrait être largement rétrocompatible :
prettier . --check # Like before, but faster
Si vous rencontrez des problèmes, vous pouvez temporairement utiliser l'ancienne CLI via une variable d'environnement :
PRETTIER_LEGACY_CLI=1 prettier . --check
Vous pouvez également l'essayer via npx, bien que npx soit lui-même assez lent :
npx prettier@next . --check
L'objectif est d'atteindre une rétrocompatibilité proche de ~100%, puis de l'intégrer simplement dans une future version stable du package prettier, remplaçant ainsi l'actuelle CLI.
Vue d'ensemble
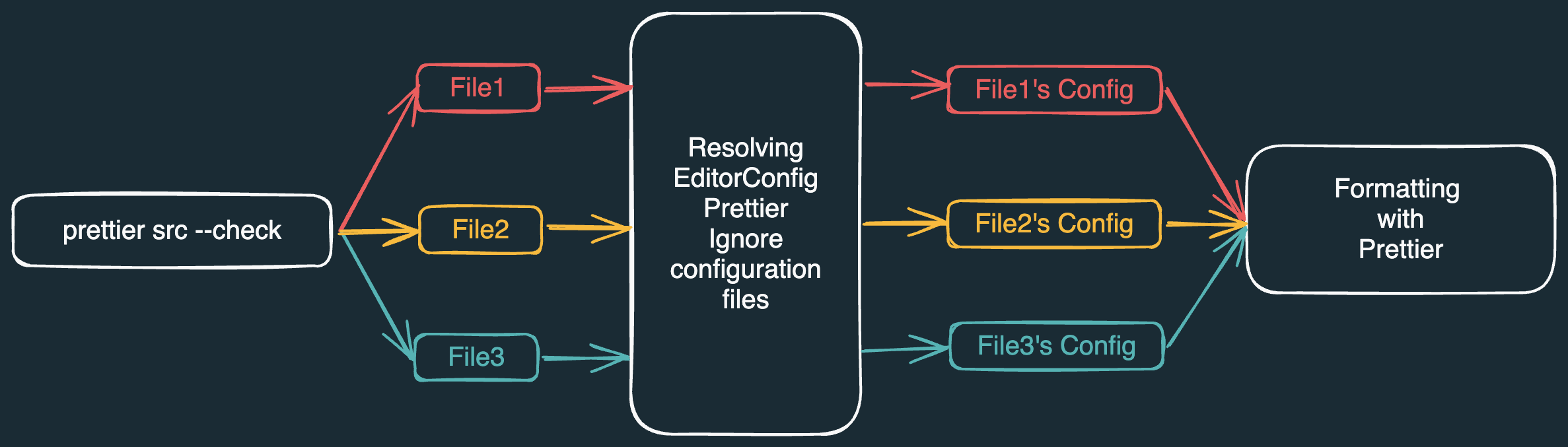
Le fonctionnement de la CLI de Prettier ressemble globalement au schéma ci-dessus :
-
Une action à exécuter sur des fichiers, par exemple vérifier s'ils sont correctement formatés.
-
Identification de tous les fichiers concernés par cette action.
-
Résolution des fichiers
.gitignoreet.prettierignorepour déterminer les fichiers à ignorer. -
Résolution des fichiers
.editorconfigpour obtenir les configurations de formatage spécifiques à EditorConfig. -
Résolution des fichiers
.prettierrcet ~10 autres pour les configurations Prettier spécifiques. -
Vérification du respect de la configuration de formatage pour chaque fichier.
-
Affichage des résultats dans le terminal.
Après cette vue d'ensemble de l'architecture de la CLI, trois observations principales se dégagent :
-
La charge de travail est proportionnelle au nombre de fichiers cibles, mais la majorité reste inchangée entre deux exécutions (ex: un commit ne modifie généralement qu'une fraction des fichiers). En mémorisant le travail précédent, on pourrait éviter de retraiter les fichiers identiques.
-
Le nombre potentiel de fichiers de configuration à résoudre est important (un dépôt peut contenir des milliers de dossiers). Par exemple, 10 fichiers
.editorconfigdifférents pourraient définir des règles pour des globs spécifiques, nécessitant une combinaison personnalisée par fichier. Heureusement, la plupart des dépôts n'ont qu'un ou quelques fichiers.editorconfig, ce qui limite l'impact. -
Observation évidente mais fondamentale : si toutes les opérations sont nécessaires et optimisées, le programme sera efficace. Notre stratégie consiste donc à éviter le travail superflu et à optimiser ce qui est indispensable.
Partant de ces constats, j'ai développé une nouvelle CLI pour Prettier à partir de zéro, car il est souvent plus simple de concevoir pour la performance dès l'origine que de tenter d'optimiser a posteriori.
Je vais utiliser le monorepo de Babel pour effectuer des mesures tout au long de cet article, car il constitue un bon point de référence, et vous donnera une idée de l'amélioration concrète dans un monorepo réel et assez volumineux.
Recherche rapide des fichiers
Tout d'abord, nous devons localiser nos fichiers cibles. L'interface CLI actuelle de Prettier utilise fast-glob pour cela, et le code correspondant ressemble à ceci :
import fastGlob from "fast-glob";
const files = await fastGlob("packages/**/*.{js,cjs,mjs}", {
ignore: ["**/.git", "**/.sl", "**/.svn", "**/.hg", "**/node_modules"],
absolute: true,
dot: true,
followSymbolicLinks: false,
onlyFiles: true,
unique: true,
});
Si nous exécutons cela sur le monorepo de Babel, nous constatons qu'il faut environ ~220ms pour trouver ~17k fichiers correspondant à nos globs, sur ~30k fichiers au total, ce qui semble raisonnablement bon, sachant que le monorepo de Babel contient également plus de 13k dossiers.
Un profilage rapide révèle qu'une part significative du temps est consacrée à vérifier si les fichiers trouvés correspondent à l'un de nos globs d'« ignore », qui semblent être convertis en regex et comparés un par un. J'ai donc tenté de fusionner les globs en un seul : "**/{.git,.sl,.svn,.hg,node_modules}", mais il semble être de nouveau scindé en interne pour une raison inconnue, sans effet notable.
En commentant entièrement nos globs d'ignore, nous pouvons retrouver pratiquement les mêmes fichiers (car presque aucun n'était réellement ignoré) en seulement ~180ms, soit ~20% de temps en moins. Si nous pouvions optimiser la correspondance de ces globs, nous pourrions réduire encore les temps.
C'est le moment de souligner que fast-glob effectue une optimisation astucieuse : si notre glob ressemble à packages/**/*.{js,cjs,mjs}, il détecte que le début est entièrement statique. Nous lui demandons en réalité de chercher **/*.{js,cjs.mjs} uniquement dans le dossier packages. Cette optimisation est significative s'il existe de nombreux fichiers dans d'autres dossiers non concernés, car ils ne seront simplement jamais scannés.
Cela m'a amené à réfléchir : nos globs d'ignore suivent le même principe, mais leur partie statique est à la fin plutôt qu'au début. J'ai donc développé une autre bibliothèque pour trouver des fichiers avec un glob capable d'exploiter également les globs avec une fin statique. Le code équivalent serait :
import readdir from "tiny-readdir-glob";
const { files } = await readdir("packages/**/*.{js,cjs,mjs}", {
ignore: "**/{.git,.sl,.svn,.hg,node_modules}",
followSymlinks: false,
});
Elle trouve les mêmes fichiers en seulement ~130ms. En commentant le glob d'ignore pour évaluer son surcoût, le temps reste similaire, ce qui indique que cette partie est désormais suffisamment optimisée pour être difficile à mesurer dans ce scénario.
Cette accélération dépasse peut-être nos attentes, pour plusieurs raisons :
-
Outre le glob d'ignore, la partie
**/*.{js,cjs,mjs}du glob principal a également été optimisée. -
Les globs sont comparés au chemin relatif d'un fichier depuis le dossier racine de recherche. Cela impliquerait normalement de nombreux appels à
path.relative. Mais pour un glob comme**/.git, le calcul du chemin relatif est inutile : nous examinons simplement la fin de la chaîne. J'ai donc supprimé complètement ces appelspath.relative. -
L'API
fs.readdirde Node est utilisée en interne par les deux bibliothèques pour scanner les répertoires. Elle fournit les noms des fichiers et dossiers trouvés, mais pas leurs chemins absolus. Nous générons ces derniers manuellement en concaténant le chemin parent et le nom avec le séparateur de chemin, plutôt qu'en appelantpath.join, ce qui accélère encore légèrement le processus.
En plus, cette nouvelle bibliothèque est environ 90 % plus légère : environ 65 Ko de code minifié ont été supprimés, ce qui accélère le démarrage de toute la CLI. Dans des dépôts bien plus petits que celui de Babel, la nouvelle CLI pourrait trouver tous les fichiers cibles avant même que l'ancienne n'ait fini d'analyser fast-glob.
Réécrire cette partie de la CLI peut sembler disproportionné par rapport au gain de vitesse obtenu, mais la raison principale est ailleurs. On pourrait penser qu'aucune optimisation ne pourrait accélérer la CLI de plusieurs secondes ici, puisque trouver les fichiers prend moins d'une demi-seconde au départ. Mais le point crucial est que pour toute la CLI, nous devons aussi trouver les fichiers de configuration. Connaître chaque fichier et dossier trouvé (même ceux ne correspondant pas à nos globs) est une information précieuse qui nous permettra de gagner plusieurs secondes plus tard. tiny-readdir-glob peut nous fournir ces données quasiment gratuitement, ce qui justifie son développement rien que pour cela.
Pour résumer les points intéressants de cette section :
-
Quand c'est possible, indiquez toujours à Prettier les extensions à chercher, par exemple avec un glob comme
packages/**/*.{js,cjs,mjs}. Si vous utilisezpackages/**/*ou simplementpackagesdans ce scénario, 13 000 fichiers supplémentaires seraient traités inutilement, ce qui coûterait plus cher à Prettier pour les ignorer ensuite. -
Il reste toujours des optimisations ou des cas spéciaux à traiter pour la performance, même dans des bibliothèques déjà optimisées, si on prend le temps de les étudier.
-
Il vaut la peine de réfléchir aux informations jetées ou difficiles à reconstituer. Ici, la bibliothèque de glob doit connaître les fichiers et dossiers trouvés pour fonctionner. Exposer ces informations à l'appelant permet d'obtenir des gains de performance supplémentaires quasi gratuitement dans certains cas.
Hypothèses pour accélérer davantage :
- Le goulot d'étranglement semble être la performance de
fs.promises.readdirdans Node, et/ou le surcoût de création d'une Promise par dossier trouvé. Il pourrait être intéressant d'explorer la version callback de cette API et les opportunités d'optimisation dans Node lui-même.
Résolution rapide des configurations
C'est probablement l'optimisation la plus impactante de la nouvelle CLI. Il s'agit de trouver les fichiers de configuration le plus vite possible, en ne vérifiant qu'une seule fois par dossier s'ils existent, et en ne parsant chaque fichier de configuration qu'une seule fois.
Un problème majeur de l'ancienne CLI était la mise en cache des configurations résolues par chemin de fichier plutôt que par dossier. Par exemple, le monorepo de Babel contient ~17 000 fichiers à formater, mais un seul fichier .editorconfig dans tout le dépôt. Nous devrions parser ce fichier une seule fois, mais il était parsé ~17 000 fois. De plus, si ces fichiers sont dans le même dossier, celui-ci était interrogé ~17 000 fois sur la présence d'un .editorconfig. Ainsi, plus les fichiers à formater étaient imbriqués profondément, plus la CLI ralentissait.
Ce problème a été résolu en deux étapes :
-
Les fichiers de configuration résolus sont maintenant mis en cache par chemin de dossier, peu importe le nombre de fichiers par dossier ou leur niveau d'imbrication.
-
Les dossiers trouvés ne sont plus interrogés sur la présence de chaque fichier de configuration (~15 formats supportés), car nous connaissons déjà tous les fichiers du dépôt (section précédente). Un simple lookup suffit, bien plus rapide qu'interroger le système de fichiers. Cela serait négligeable dans les petits dépôts, mais pour Babel (~13 000 dossiers), 13 000 * 15 vérifications système s'accumulaient~~ se multipliaient rapidement.
Examinons maintenant plus en détail la résolution de chaque type de configuration spécifique.
Résolution des configurations EditorConfig
En supposant que nous ayons déjà analysé chaque fichier .editorconfig du dépôt et que nous puissions récupérer les fichiers pertinents pour n'importe quel fichier cible en temps constant, notre objectif est maintenant de fusionner ces configurations en un seul objet par fichier cible.
Cette idée devient immédiatement problématique car le package editorconfig ne fournit pas de fonction pour cette opération. L'option la plus proche est parseFromFiles (dépréciée), qui semble correspondre mais nécessite les configurations sous forme de chaînes. Elle les réanalyserait donc à chaque appel, ce que nous voulons justement éviter puisque nous souhaitons n'effectuer ce parsing qu'une seule fois.
Le package a donc été réécrit pour les besoins de Prettier : tiny-editorconfig fournit exactement la fonction resolve requise. Il délègue la logique de recherche des fichiers de configuration, ce qui correspond parfaitement à notre besoin de mise en cache personnalisée.
J'en ai profité pour réécrire aussi le parseur INI sous-jacent, qui s'avère ~9x plus rapide. L'impact est limité (la plupart des dépôts n'ont qu'un seul .editorconfig), mais j'apprécie ce genre d'optimisations - et si votre dépôt contient des milliers de fichiers .editorconfig, vous profiterez pleinement du gain !
Ce nouveau librairie est également ~82% plus légère : ~50kb de code minifié supprimés, accélérant ainsi le démarrage du CLI. Autre avantage : il utilise la même bibliothèque glob que tiny-readdir-glob, là où l'ancien CLI utilisait fast-glob et editorconfig avec des implémentations différentes - une réduction de code supplémentaire en pratique.
Le traitement du monorepo de Babel prenait plusieurs secondes auparavant, il s'exécute désormais en ~100ms.
Hypothèses pour accélérer davantage :
- Pré-résoudre ces configurations pour tous les chemins possibles (dans la plupart des cas). Selon les globs utilisés, on pourrait par exemple obtenir au maximum 3 configurations distinctes : pour les fichiers ne correspondant à aucun glob, ceux correspondant à
**/*.js, et ceux correspondant à**/*.md. L'implémentation serait complexe et le gain incertain, mais l'idée mérite exploration.
Résolution des configurations Prettier
Pour les configurations spécifiques à Prettier (comme .prettierrc), nous partons du même principe : tous les fichiers de configuration sont résolus et accessibles en temps constant pour chaque fichier cible.
La situation est identique à celle des configurations EditorConfig. Nous appliquerons donc la même approche, en intégrant directement la logique de fusion dans le CLI (créer un package dédié n'apporterait aucune valeur à l'écosystème).
Les principaux aspects à considérer pour l'avenir sont selon moi :
-
Le nombre élevé de formats de configuration supportés. Dans le monorepo de Babel, cela génère ~150k recherches dans l'objet des chemins connus (créé à l'étape 1). Bien que non prohibitif, ce coût n'est pas négligeable. Réduire ce nombre accélérerait sensiblement le processus.
-
Certains parseurs nécessaires sont relativement lourds :
json5contient ~100x plus de code que le plus léger parseur JSONC connu en JavaScript, et peut être ~50x plus lent. Réduire les formats supportés allégerait le CLI. -
Si nous pouvions vérifier une seule fois si un fichier nommé par exemple
.prettierrc.json5existe dans le dépôt, nous pourrions réduire d'un ordre de grandeur le nombre de vérifications de ces fichiers de configuration. En effet, si aucun fichier portant ce nom n'est trouvé dans le dépôt, nous n'avons pas besoin d'interroger chacun des ~13 000 dossiers de Babel. La liste de tous les noms de fichiers connus est un autre élément d'information précieux que la bibliothèque glob que nous utilisons pourrait nous fournir gratuitement.
Résolution des configurations d'ignorance
Enfin, nous devons résoudre les fichiers .gitignore et .prettierignore pour déterminer quels fichiers trouvés doivent être ignorés. Nous supposons également que nous avons déjà résolu tous ceux qui ont été trouvés et que nous pouvons les récupérer en temps constant pour n'importe quel fichier cible.
Je n'applique pas d'optimisations majeures ici, je demande principalement à node-ignore de nous fournir une fonction que nous pouvons appeler pour vérifier si un fichier doit être ignoré.
Une petite optimisation consiste toutefois à éviter d'appeler path.relative et la fonction ignore elle-même dans certains cas. Les fichiers ignore correspondent plus ou moins au chemin relatif des fichiers trouvés depuis le dossier où ils se trouvent. Comme nous savons que tous les chemins traités sont normalisés, si le chemin absolu d'un fichier cible ne commence pas par le chemin absolu du dossier contenant un fichier ignore, cela signifie que ce fichier est en dehors du périmètre géré par ce fichier ignore. Nous pouvons donc éviter d'appeler la fonction ignore que node-ignore a créée pour nous.
Une part non négligeable du temps semble consacrée à la correspondance des globs dans ces fichiers avec les fichiers trouvés - des centaines de millisecondes pour des milliers de fichiers. Cela s'explique par le fait qu'il peut y avoir un grand nombre de globs dans ces fichiers et un grand nombre de fichiers à comparer, dont le produit donne approximativement le nombre de tentatives de correspondance de globs dans le pire des cas.
L'avantage des fichiers .gitignore et .prettierignore est qu'ils se rentabilisent souvent : le temps passé à les analyser et à faire correspondre les fichiers est généralement inférieur au temps nécessaire pour traiter chaque fichier qui aurait été exclu par eux.
Hypothèses pour accélérer davantage :
-
Peut-être que la plupart de ces globs pourraient être fusionnés en un seul glob plus complexe et vérifiés en une seule fois par le moteur, puisque nous ne cherchons pas à savoir quel glob correspond exactement, seulement si au moins l'un d'eux correspond.
-
Peut-être que les globs pourraient être exécutés dans un ordre différent, par exemple en priorisant les globs les moins coûteux et les plus larges, ce qui permettrait de réduire le temps moyen de correspondance. Cela ne ferait aucune différence si la plupart des fichiers trouvés ne sont pas ignorés.
-
Nous pourrions mémoriser quels chemins de fichiers correspondent ou non à l'aide d'un cache, mais il semble possible d'accélérer significativement ce processus sans recourir au cache.
Mise en cache
À ce stade, nous avons trouvé tous les fichiers et résolu toutes les configurations. Il reste à effectuer le travail potentiellement coûteux de formater chaque fichier cible, et c'est là qu'intervient la mise en cache.
La CLI actuelle prend en charge une forme de mise en cache, mais elle est facultative (nécessitant le flag explicite --cache) et ne se souvient pas si un fichier lors de l'exécution précédente a été jugé non formaté correctement - seulement s'il était correctement formaté. Cela peut entraîner une surcharge inutile dans certains cas, car ces fichiers non formatés seraient à nouveau formatés pour vérification alors que nous aurions pu conserver cette information de l'exécution précédente.
Notre objectif ici est de sauter le maximum de travail possible en mémorisant si un fichier était formaté ou non, tout en générant des fichiers de cache raisonnablement petits et sans introduire de surcharge importante avec le mécanisme de cache lui-même.
La nouvelle CLI dispose plutôt d'un cache désactivable, donc la mise en cache est toujours activée par défaut, sauf si vous la désactivez explicitement avec un drapeau --no-cache. Ainsi, ses bénéfices atteignent naturellement bien plus d'utilisateurs. Le cache est maintenant activé par défaut car il prend tout en compte, rendant peu réaliste qu'il fournisse des informations incorrectes. Si l'un des éléments suivants change, le cache (ou des parties) est automatiquement invalidé : la version de Prettier, tous les fichiers de configuration EditorConfig/Prettier/Ignore résolus et leurs chemins, les options de formatage passées via des drapeaux CLI, le contenu réel de chaque fichier et le chemin de chaque fichier.
L'astuce principale ici est d'éviter que le cache de chaque fichier dépende directement de sa configuration de formatage résolue. Cela nécessiterait de fusionner ces fichiers de configuration pour chaque fichier cible, de sérialiser l'objet résultant et de le hacher – opération potentiellement trop coûteuse.
La nouvelle CLI se contente plutôt d'analyser tous les fichiers de configuration trouvés, puis de les sérialiser et hacher. Cela prend un temps constant, quel que soit le nombre de fichiers à formater ultérieurement, et ne nécessite qu'un seul hash mémorisé dans le fichier de cache pour tenir compte indirectement des fichiers de configuration. C'est sécurisé car si les chemins des fichiers de configuration et leur contenu ne changent pas, tout fichier avec le même chemin que lors de l'exécution précédente utilisera nécessairement la même configuration de formatage résolue. Le seul risque potentiel serait un bug dans une dépendance d'analyse de configuration, mais au pire, la version de Prettier peut être mise à jour en même temps que la dépendance problématique.
Pour donner des chiffres : la CLI actuelle vérifie le monorepo de Babel sans cache en ~29 secondes, la nouvelle CLI nécessite ~7,5s sans cache ni parallélisation. Avec le cache activé et existant, la CLI actuelle prend encore ~22 secondes contre ~1,3s pour la nouvelle CLI – un temps qui pourrait probablement être réduit de moitié avec davantage d'optimisations futures.
S'il ne faut retenir qu'une chose de cet article : pour maximiser la vitesse de la CLI, conservez le fichier de cache. Par défaut, il se trouve sous ./node_modules/.cache/prettier, et son emplacement est personnalisable via le drapeau --cache-location <path>. Je le répète : si la performance compte dans votre scénario, conserver le fichier de cache entre les exécutions est LA mesure la plus impactante.
Hypothèses pour accélérer davantage :
-
Optimiser le hachage dans Node. Bun calcule les mêmes hashs ~3x plus vite, donc une marge de progression existe. J'ai signalé cela à Node – aucune PR corrective n'a encore été soumise, la tâche semble complexe.
-
Les fichiers de configuration analysés pourraient aussi être mis en cache, plutôt que de simplement mémoriser leur hash, mais il n'y en a généralement qu'une poignée, donc le gain serait probablement marginal.
-
Davantage de code pourrait être supprimé ou chargé à la demande, accélérant légèrement le chemin entièrement mis en cache.
Formatage
Nous approchons de la fin du pipeline : nous connaissons les fichiers à formater et devons simplement exécuter cette étape.
Je n'ai pas beaucoup optimisé la fonction centrale de formatage elle-même, car elle semble déjà raisonnablement rapide pour peu de fichiers. La majorité des ralentissements CLI provenaient d'une résolution inefficace des configurations et de l'absence de mémorisation du travail passé. Ce pourrait être la prochaine piste majeure, même si aucune opportunité d'optimisation évidente n'est apparue lors d'un profilage rapide.
J'ai toutefois testé quelques autres approches.
Tout d'abord, plusieurs fichiers peuvent être formatés en parallèle. C'est maintenant le comportement par défaut, avec une option --no-parallel pour le désactiver. Le flag --parallel-workers <int> permet aussi de définir un nombre personnalisé de workers pour un réglage fin. Sur mon ordinateur à 10 cœurs avec le parallélisme, le temps nécessaire pour vérifier le monorepo de Babel passe de ~7,5s à ~5,5s, ce qui n'est pas particulièrement impressionnant. Je ne suis pas sûr de ne pas obtenir une meilleure scalabilité, j'aimerais examiner cela ultérieurement. Cependant, pour des dépôts bien plus grands et des machines CI avec des centaines de cœurs, la différence pourrait être bien plus significative pour votre cas d'usage, en plus des autres optimisations.
Enfin, j'ai rapidement testé le remplacement de la fonction de formatage de Prettier par @wasm-fmt/biome_fmt, la fonction de formatage de Biome compilée en WASM. J'obtiens ~3,5s pour vérifier le monorepo de Babel sans parallélisation, et ~2,2s avec. Soit environ 2 fois mieux qu'avec le formateur natif de Prettier. Potentiellement, le gain pourrait être encore plus important si la fonction de Biome était compilée en module natif Node, je n'en suis pas certain.
Hypothèses pour accélérer davantage :
-
Je n'ai pas beaucoup travaillé sur le cœur du formatage, qui semble environ 2 fois plus lent qu'optimal, mais l'effort requis pourrait être conséquent. Il reste clairement une marge d'amélioration.
-
Le flag
--parallel, bien qu'activé par défaut, présente un inconvénient mineur : avec peu de fichiers à formater mais beaucoup de cœurs disponibles, chaque cœur reçoit peu de fichiers, ce qui peut légèrement ralentir le processus. Ceci pourrait être résolu par un dimensionnement dynamique du pool via des heuristiques. Il reste activé par défaut car il ne ralentit significativement que dans des scénarios déjà rapides, tout en offrant des gains importants dans les cas critiques.
Affichage dans le terminal
La dernière étape consiste simplement à afficher dans le terminal le résultat de la commande exécutée.
Peu d'optimisations étaient possibles ici, mais quelques-unes ont été identifiées :
-
Dans certains cas (ex: formatage de nombreux petits fichiers), l'ancien CLI affichait immédiatement le chemin du fichier en cours de formatage pour l'effacer une milliseconde plus tard. Cette approche coûte cher avec des milliers de fichiers : les appels
console.logsynchrones bloquent le thread principal, et un rafraîchissement d'écran ne montrant qu'une fraction des messages rend l'opération inutile. Le nouveau CLI n'affiche plus les fichiers en cours de traitement, gagnant ainsi des centaines de millisecondes. -
Enfin, l'ancien CLI pouvait appeler
console.logdes milliers de fois, selon le nombre de fichiers à formater, tandis que le nouveau regroupe les logs et effectue un seulconsole.logà la fin, ce qui peut être étonnamment plus rapide dans certains cas.
La principale piste d'amélioration ici serait un affichage visuellement engageant (pour une meilleure performance perçue) sans alourdir le traitement.
Résultats
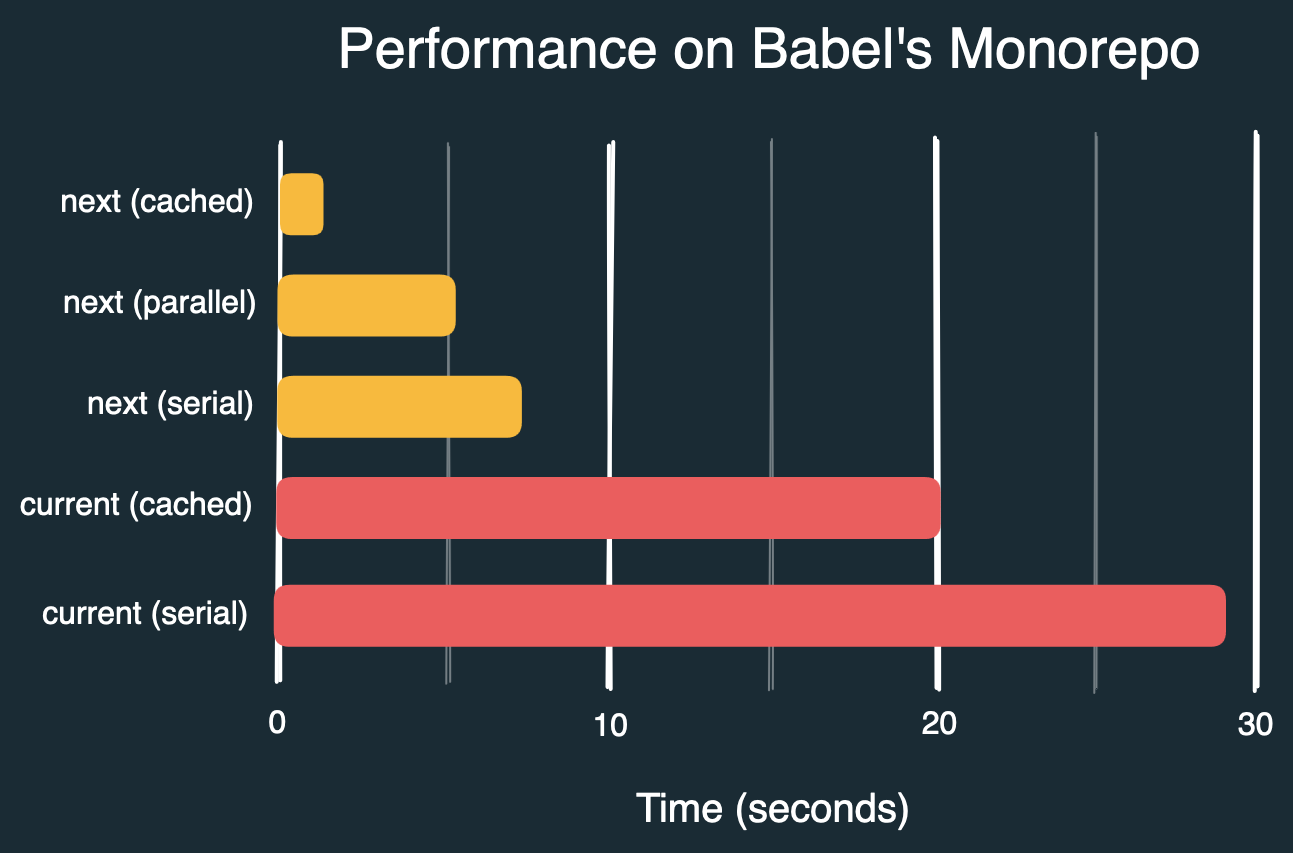
Avant de conclure, voici les chiffres obtenus lors de la vérification du monorepo de Babel (tous fichiers formatés sauf 9 en erreur), avec différents flags, comparant l'ancien et le nouveau CLI :
prettier packages --check # 29s
prettier packages --check --cache # 20s
prettier@next packages --check --no-cache --no-parallel # 7.3s
prettier@next packages --check --no-cache # 5.5s
prettier@next packages --check # 1.3s
Par défaut, les temps d'exécution pour la même commande passent de ~29s à ~1,3s, soit une accélération d'environ 22x. Cela nécessite que le fichier de cache soit conservé entre les exécutions. Nous pourrons probablement atteindre une accélération proche de 50x à l'avenir.
Si le fichier de cache n'est pas conservé, si vous désactivez explicitement le cache, ou s'il s'agit de la première exécution, les temps passent de ~29s à ~5,5s avec le parallélisme sur mon ordinateur, soit une accélération d'environ 5x, ce qui reste très significatif.
Il est important de souligner que cette amélioration est obtenue sans aucune modification de la fonction format de Prettier elle-même.
Résultats comparés à Biome
Il est intéressant de comparer nos chiffres avec ceux de Biome, le formateur Rust leader et probable champion des performances :
biome format packages
# Diagnostics not shown: 25938.
# Compared 28703 file(s) in 869ms
# Skipped 4770 file(s)
Ici, Biome vérifie le formatage pour environ 11 000 fichiers supplémentaires par rapport à notre CLI, car il ne semble pas encore gérer la résolution des fichiers .gitignore et/ou .prettierignore. Il peut aussi exister d'autres différences de comportement potentiellement significatives.
Une modification manuelle de notre CLI pour désactiver la gestion des fichiers d'ignore, afin de se rapprocher du comportement de Biome, donne le résultat suivant :
prettier@next packages --check --no-cache # 15s
Cette comparaison est à prendre avec précaution car les deux outils ne font pas exactement la même chose, mais il est intéressant de constater la vitesse à laquelle Biome peut vérifier le formatage de nombreux fichiers. Une vitesse que nous ne pourrons probablement égaler qu'avec un système de cache.
Différentes approches pour tenter d'accélérer massivement l'expérience utilisateur.
Conclusion
La nouvelle CLI est encore en développement, mais nous sommes impatients que vous l'essayiez ! Vous pouvez l'installer dès aujourd'hui.
Je serais curieux de connaître l'accélération que la nouvelle CLI vous apporte. N'hésitez pas à tweeter vos résultats à @PrettierCode ou directement à @fabiospampinato, surtout si vous avez des questions ou des idées pour accélérer davantage les choses.