CLI de Prettier: Análisis Profundo de Rendimiento

Esta página fue traducida por PageTurner AI (beta). No está respaldada oficialmente por el proyecto. ¿Encontraste un error? Reportar problema →
Hola, soy Fabio y el equipo de Prettier me contrató para acelerar la interfaz de línea de comandos (CLI) de Prettier. En este artículo exploraremos las optimizaciones que descubrí, el proceso que llevó a encontrarlas, cifras comparativas entre la CLI actual y la nueva, y algunas hipótesis sobre futuras optimizaciones.
Instalación
La nueva CLI en desarrollo para Prettier acaba de ser publicada y puedes instalarla ahora:
npm install prettier@next
Debería ser ampliamente compatible con versiones anteriores:
prettier . --check # Like before, but faster
Si encuentras problemas, puedes usar temporalmente la CLI anterior mediante una variable de entorno:
PRETTIER_LEGACY_CLI=1 prettier . --check
También puedes probarla con npx, aunque npx es bastante lento por sí mismo:
npx prettier@next . --check
El objetivo es lograr una compatibilidad casi ~100% hacia atrás, para luego integrarla en una futura versión estable del paquete prettier, reemplazando la CLI actual.
Visión general
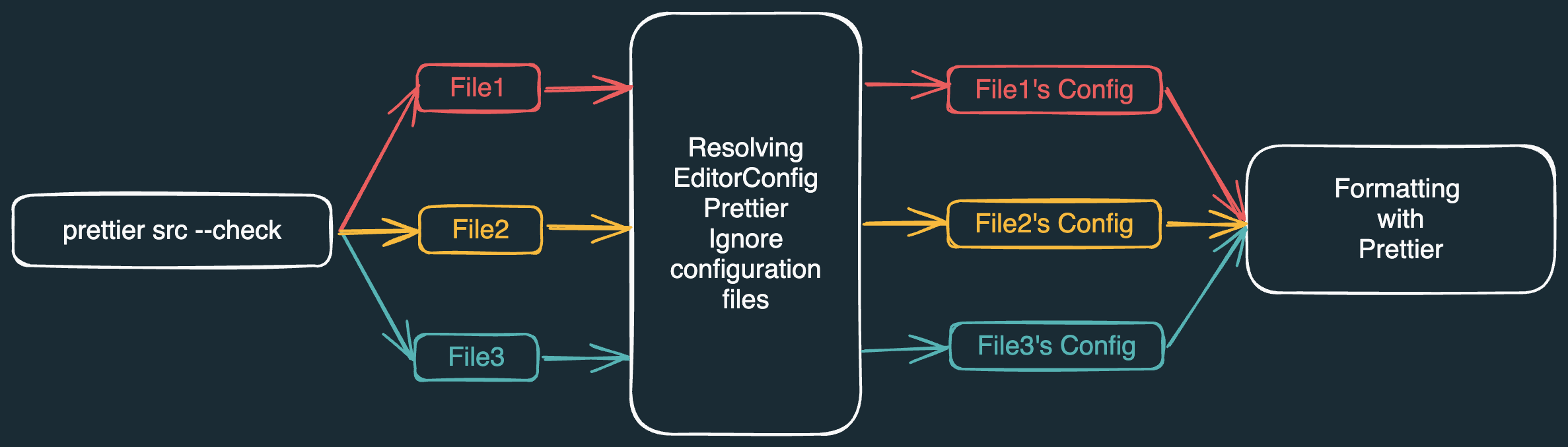
La CLI de Prettier funciona aproximadamente como en el diagrama anterior:
-
Existe alguna acción que queremos ejecutar sobre archivos, por ejemplo verificar si están formateados correctamente.
-
Necesitamos encontrar todos los archivos sobre los que ejecutar esta acción.
-
Debemos resolver archivos
.gitignorey.prettierignorepara determinar qué archivos ignorar. -
Necesitamos resolver archivos
.editorconfigpara configuraciones específicas de EditorConfig aplicables a esos archivos. -
Debemos resolver archivos
.prettierrcy ~10 más para configuraciones específicas de Prettier. -
Debemos verificar si cada archivo cumple con su configuración de formato.
-
Finalmente necesitamos mostrar algún tipo de resultado en la terminal.
Tras esta visión general de la arquitectura del CLI, considero tres observaciones principales:
-
La carga de trabajo escala con el número de archivos, pero la mayoría permanece inalterada entre ejecuciones. En repositorios grandes, un commit suele afectar solo una fracción de archivos. Si recordáramos el trabajo previo, podríamos omitir gran parte del procesamiento actual.
-
Existe potencialmente un gran volumen de archivos de configuración por resolver. Un repositorio con miles de carpetas podría contener múltiples archivos de configuración. Por ejemplo, 10 archivos
.editorconfigdistintos podrían definir configuraciones mediante globs que deben combinarse específicamente para cada archivo destino. Pero en la práctica, la mayoría de repositorios contienen solo uno o pocos archivos.editorconfig, incluso con miles de carpetas, lo que minimiza este costo. -
Esta observación no es particularmente reveladora, pero si un programa realiza solo trabajo necesario y lo hace eficientemente, entonces será intrínsecamente eficiente. Por tanto, nuestra estrategia es omitir trabajo innecesario siempre que sea posible y optimizar lo inevitable.
Con estas premisas, comencé a desarrollar una nueva CLI para Prettier desde cero, pues suele ser más sencillo construir con enfoque en rendimiento desde el inicio que adaptar soluciones existentes.
Utilizaré el monorepo de Babel para realizar mediciones a lo largo de esta publicación, ya que ofrece un buen punto de referencia. Esto te dará una idea práctica de la mejora en un monorepo real de tamaño considerable.
Encontrar archivos rápidamente
Primero necesitamos localizar nuestros archivos objetivo. La CLI actual de Prettier usa fast-glob para esto, y el código podría verse así:
import fastGlob from "fast-glob";
const files = await fastGlob("packages/**/*.{js,cjs,mjs}", {
ignore: ["**/.git", "**/.sl", "**/.svn", "**/.hg", "**/node_modules"],
absolute: true,
dot: true,
followSymbolicLinks: false,
onlyFiles: true,
unique: true,
});
Si ejecutamos esto en el monorepo de Babel, veremos que tarda ~220ms en encontrar ~17k archivos que coinciden con nuestros globs, de ~30k archivos totales encontrados. Esto parece razonablemente bueno, considerando que el monorepo de Babel contiene más de 13k carpetas.
Con un perfilado rápido podemos detectar que una parte significativa del tiempo se dedica a verificar si los archivos encontrados coinciden con alguno de nuestros globs de "ignorar", que internamente se convierten en expresiones regulares y se evalúan una por una. Intenté fusionar los globs en uno solo: "**/{.git,.sl,.svn,.hg,node_modules}", pero internamente se vuelven a separar por alguna razón, así que eso no cambió nada.
Si comentamos completamente los globs de ignorar, podemos encontrar prácticamente los mismos archivos (ya que casi ninguno fue ignorado) en ~180ms, un ~20% menos de tiempo. Si pudiéramos comparar esos globs de manera más eficiente, podríamos reducir aún más los tiempos.
Es buen momento para mencionar que fast-glob hace una optimización interesante: si nuestro glob luce así: packages/**/*.{js,cjs,mjs}, puede detectar que el inicio es completamente estático. Lo que realmente pedimos es buscar **/*.{js,cjs.mjs} solo dentro de la carpeta packages. Esta optimización es significativa cuando hay muchos archivos en otras carpetas irrelevantes, ya que simplemente no se escanearán.
Esto me hizo pensar: nuestros globs de ignorar son básicamente iguales, pero la parte estática está al final, no al inicio. Así que escribí otra biblioteca para encontrar archivos que aprovecha globs con final estático. El código equivalente sería:
import readdir from "tiny-readdir-glob";
const { files } = await readdir("packages/**/*.{js,cjs,mjs}", {
ignore: "**/{.git,.sl,.svn,.hg,node_modules}",
followSymlinks: false,
});
Y encuentra los mismos archivos en ~130ms. Si comentamos el glob de ignorar (para medir su sobrecarga), parece tomar el mismo tiempo, lo que indica que está suficientemente optimizado para este escenario.
La mejora fue mayor de lo esperado por varias razones:
-
Además del glob de ignorar, la parte
**/*.{js,cjs,mjs}del glob principal también se optimizó. -
Los globs se comparan con la ruta relativa del archivo desde la carpeta raíz. Esto implicaría llamadas a
path.relative, pero con un glob como**/.git, da igual calcular la ruta relativa: basta buscar el final de la cadena. Así que omití esas llamadas apath.relativecompletamente. -
La API
fs.readdirde Node se usa internamente en ambas bibliotecas. Devuelve nombres de archivos/carpetas, no rutas absolutas. Podemos generarlas manualmente concatenando la ruta padre y el nombre con el separador de ruta, en lugar de usarpath.join, lo que acelera un poco más.
Además, esta nueva biblioteca es un 90% más pequeña: ya no se necesitan unos 65kb de código minificado, lo que acelera el inicio de la CLI. En repositorios más pequeños que el de Babel, la nueva CLI podría encontrar todos los archivos objetivo para cuando la antigua apenas terminara de analizar fast-glob.
Reescribir esta parte de la CLI podría parecer excesivo para la mejora de velocidad obtenida, pero la razón principal es otra. Parecería que no podríamos hacer nada para acelerar la CLI en varios segundos, ya que encontrar todos los archivos tarda menos de medio segundo. Pero el punto crucial es que para toda la CLI no solo necesitamos encontrar archivos para formatear, sino también archivos de configuración. Conocer cada archivo y carpeta encontrados, incluso si no coincidieron con nuestros globs, es información muy valiosa que nos permitirá ahorrar varios segundos después. tiny-readdir-glob puede darnos esa información prácticamente sin costo adicional, por lo que valió la pena desarrollarlo solo por eso.
Para resumir los puntos quizá más interesantes de esta sección:
-
Siempre que puedas, especifica a Prettier las extensiones a buscar, por ejemplo con un glob como
packages/**/*.{js,cjs,mjs}. Si usaraspackages/**/*o solopackagesen este escenario, se procesarían 13k archivos adicionales y sería más costoso descartarlos después. -
Siempre queda algo por optimizar o casos especiales para mejorar el rendimiento, incluso en bibliotecas ya optimizadas, si se dedica tiempo a investigarlo.
-
Vale la pena reflexionar sobre qué información se está descartando o resulta costosa de reconstruir. Aquí, la biblioteca de globs debe conocer los archivos y carpetas encontrados para funcionar; exponer esa información al usuario permite mejorar el rendimiento básicamente gratis en algunos casos.
Conjeturas sobre cómo acelerar esto aún más:
- Parece estar limitado por el rendimiento de
fs.promises.readdiren Node y/o la sobrecarga de crear una Promise por cada carpeta encontrada. Valdría la pena explorar el uso de la versión con callbacks de esa API y oportunidades de optimización en el propio Node.
Resolución rápida de configuraciones
Esta es posiblemente la optimización más impactante detrás de la nueva CLI. Consiste básicamente en encontrar archivos de configuración lo más rápido posible, verificando una sola vez si cada carpeta contiene estos archivos y analizando los encontrados una única vez.
Un problema clave en la CLI actual es que almacena en caché las configuraciones resueltas por ruta de archivo, no por ruta de carpeta. Por ejemplo, el monorepo de Babel tiene ~17k archivos para formatear, pero solo 1 archivo .editorconfig en todo el repositorio. Deberíamos analizar ese archivo una vez, pero en cambio se analizó ~17k veces. Además, si imaginas esos ~17k archivos en la misma carpeta, a esa carpeta se le preguntó si contenía un .editorconfig ~17k veces. Cuanto más anidados estuvieran los archivos en carpetas, más lenta se volvía la CLI.
Este problema se resolvió principalmente en dos pasos:
-
Los archivos de configuración resueltos ahora se almacenan en caché por ruta de carpeta, sin importar cuántos archivos contenga cada carpeta o su nivel de anidamiento.
-
Ahora casi no se pregunta a las carpetas encontradas si contienen cada uno de los ~15 archivos de configuración admitidos, porque conocemos todos los archivos del repositorio desde la sección anterior y podemos hacer una simple búsqueda allí. Esto resulta mucho más rápido que consultar el sistema de archivos. En repos pequeños no importaría mucho, pero en el de Babel (~13k carpetas), 13k * 15 consultas al sistema de archivos se multiplicaban rápidamente.
Profundicemos ahora en cómo se resuelve cada tipo específico de configuración admitida.
Resolución de configuraciones EditorConfig
Partiendo de la premisa de que ya hemos analizado todos los archivos .editorconfig del repositorio y podemos recuperar los relevantes para cualquier archivo objetivo en tiempo constante, lo que queremos hacer ahora es fusionarlos en un único objeto de configuración para cada archivo objetivo, básicamente.
Esta idea se complica de inmediato porque el paquete editorconfig no proporciona una función para hacerlo. La más cercana parece ser parseFromFiles, que además de estar obsoleta parece hacer lo que necesitamos, pero requiere las configuraciones como cadenas de texto, por lo que presumiblemente las analizará internamente en cada llamada, que es precisamente lo que queríamos evitar desde el principio: solo queremos analizarlas una única vez.
Por eso reescribimos ese paquete para las necesidades de Prettier. tiny-editorconfig proporciona exactamente la función resolve que necesitamos y deja la lógica de búsqueda de archivos de configuración en nuestras manos, que es lo que queremos porque necesitamos almacenar estos archivos en caché de forma personalizada.
De paso, también reescribí el analizador INI subyacente, que parece ser ~9 veces más rápido. No debería importar mucho, ya que la mayoría de los repos solo tendrán un archivo .editorconfig, pero disfruto escribir estos pequeños parsers, ¡y si tienes miles de archivos .editorconfig en tu repo, notarás esa mejora extra de rendimiento!
Además, esta nueva biblioteca es ~82% más pequeña: eliminamos ~50kb de código minificado, lo que acelera el arranque de toda la CLI. También usa la misma librería de glob que tiny-readdir-glob, mientras que en la CLI actual fast-glob y editorconfig usan diferentes, así que en realidad se eliminó efectivamente un poco más de código que eso.
Anteriormente, resolver estos archivos para el monorepo de Babel tomaba varios segundos; ahora toma aproximadamente ~100ms.
Conjeturas sobre cómo acelerar esto aún más:
- Debería ser posible en algunos (¿la mayoría?) casos pre-resolver estos archivos de configuración para cualquier ruta de archivo que podamos encontrar. Por ejemplo, dependiendo de los globs en ellos, podríamos terminar con como máximo 3 configuraciones resueltas posibles: una para archivos que no coinciden con ningún glob, otra para archivos que coinciden con el glob
**/*.js, y otra para los que coinciden con**/*.md. Es complicado de implementar y no está claro cuál será la mejora en la práctica, pero es algo a considerar en el futuro.
Resolución de configuraciones de Prettier
Para configuraciones específicas de Prettier, como el archivo .prettierrc, también asumimos que hemos resuelto todos los archivos de configuración encontrados y podemos recuperarlos en tiempo constante para cualquier archivo objetivo.
Es básicamente idéntico a lo que teníamos para las configuraciones de EditorConfig, así que haremos lo mismo, esta vez codificando directamente en la CLI la lógica para fusionar las configuraciones, ya que crear un paquete independiente para ello parece tener prácticamente ninguna utilidad para el ecosistema.
Los principales aspectos a considerar aquí para el futuro son, en mi opinión:
-
Se admite una gran cantidad de formatos de configuración diferentes. En el monorepo de Babel esto se traduce en ~150k búsquedas en el objeto de rutas conocidas que creamos en el primer paso, lo cual, aunque no es súper costoso, tampoco es gratuito. Si este número pudiera reducirse mucho, aceleraría un poco las cosas.
-
Algunos de los parsers necesarios para analizar esos archivos de configuración son relativamente costosos. El parser
json5requiere ~100 veces más código que el parser JSONC (JSON con Comentarios) más pequeño que conozco para JavaScript, y en algunos casos es ~50 veces más lento en el análisis. Si se pudieran admitir menos formatos, la CLI resultaría más ligera. -
Si pudiéramos verificar una sola vez si existe un archivo llamado, por ejemplo,
.prettierrc.json5en cualquier parte del repositorio, podríamos reducir drásticamente el número de verificaciones para estos archivos de configuración. Si ningún archivo con ese nombre se encuentra en el repositorio, entonces no necesitamos preguntar a cada uno de los ~13k directorios de Babel si lo tienen. La lista de todos los nombres de archivo conocidos es otra información valiosa que la biblioteca de globs que utilizamos podría proporcionarnos gratuitamente.
Resolución de configuraciones de ignorado
Finalmente, necesitamos resolver archivos .gitignore y .prettierignore para determinar qué archivos encontrados deben ignorarse. Asumimos también que ya hemos resuelto todos los encontrados y podemos recuperarlos en tiempo constante para cualquier archivo objetivo.
No estoy implementando optimizaciones significativas aquí, básicamente estoy solicitando a node-ignore que genere una función que podamos llamar para verificar si un archivo debe ignorarse.
Una pequeña optimización es omitir llamar a path.relative y a la función ignore en ciertos casos. Los archivos de ignorado coinciden aproximadamente con la ruta relativa de los archivos encontrados desde el directorio donde reside el archivo de ignorado. Como sabemos que todas las rutas están normalizadas, si la ruta absoluta de un archivo objetivo no comienza con la ruta absoluta del directorio del archivo de ignorado, ese archivo está fuera del ámbito gestionado por dicho archivo, por lo que no necesitamos invocar la función ignore que node-ignore creó para nosotros.
Sin embargo, parece que se dedica un tiempo considerable a emparejar los globs de estos archivos con los archivos encontrados—cientos de milisegundos para miles de archivos. Esto se debe a que puede haber muchos globs en estos archivos y muchos archivos para comparar, cuya multiplicación da aproximadamente el número máximo de intentos de coincidencia de globs.
Lo positivo de los archivos .gitignore y .prettierignore es que suelen compensar el costo: el tiempo dedicado a analizarlos y emparejar archivos es generalmente menor que el tiempo requerido para procesar cada archivo que hubieran descartado.
Conjeturas sobre cómo acelerar esto aún más:
-
Quizás la mayoría de esos globs podrían combinarse en un único glob más complejo y compararse simultáneamente, ya que solo nos interesa saber si algún glob coincide, no cuál específicamente.
-
Tal vez los globs podrían ejecutarse en un orden diferente: procesar primero los globs más simples y amplios podría reducir el tiempo promedio de comparación. Aunque esto no ayudaría si la mayoría de los archivos encontrados no se ignoran.
-
Podríamos memorizar qué rutas coinciden mediante una caché, pero parece factible acelerarlo significativamente sin recurrir a este mecanismo.
Caché
En este punto ya hemos encontrado todos los archivos y analizado las configuraciones. Lo que queda es realizar el trabajo potencialmente costoso: formatear cada archivo objetivo. Aquí es donde entra la caché.
La CLI actual soporta cierto nivel de caché, pero es opcional (requiere la bandera --cache explícita) y solo recuerda si un archivo estaba correctamente formateado en ejecuciones anteriores—no detecta archivos mal formateados. Esto genera sobrecarga innecesaria, ya que esos archivos se volverían a formatear para verificar su estado, pudiendo haberse evitado al recordar su estado previo.
El objetivo es omitir la mayor cantidad de trabajo posible: recordar si un archivo estaba formateado o no, generando archivos de caché razonablemente pequeños y minimizando la sobrecarga del propio mecanismo de caché.
La nueva CLI tiene caché de exclusión voluntaria, por lo que la caché está siempre activada a menos que la desactives explícitamente con la bandera --no-cache. De esta forma, sus beneficios llegarán por defecto a muchos más usuarios. Además, la caché ahora está activada por defecto porque considera todos los factores, lo que hace poco probable que proporcione información incorrecta. Si alguno de los siguientes elementos cambia, la caché (o partes de ella) se invalidará automáticamente: la versión de Prettier, todos los archivos de configuración de EditorConfig/Prettier/Ignore resueltos y sus rutas, las opciones de formato proporcionadas mediante banderas CLI, el contenido real de cada archivo y la ruta de cada archivo.
El truco principal aquí es que no queremos que la caché de cada archivo dependa directamente de su configuración de formato resuelta, porque eso requeriría combinar esos archivos de configuración para cada archivo objetivo, serializar el objeto resultante y calcular su hash, lo cual sería más costoso de lo deseable.
Lo que hace la nueva CLI en su lugar es simplemente analizar todos los archivos de configuración encontrados, serializarlos y calcular su hash. Esto toma una cantidad constante de tiempo sin importar cuántos archivos necesitemos formatear después, y solo requiere recordar un único hash en el archivo de caché para considerar indirectamente los archivos de configuración. Esto es seguro porque si las rutas a los archivos de configuración y sus contenidos no cambian, entonces cualquier archivo con la misma ruta que en la ejecución anterior necesariamente se formateará con el mismo objeto de configuración resuelto. El único problema potencial sería si alguna dependencia usada para analizar esos archivos de configuración tuviera errores, pero en el peor de los casos, se puede actualizar la versión de Prettier junto con la dependencia problemática.
Para contextualizar con cifras: la CLI actual verifica el monorepo de Babel sin caché en ~29 segundos, mientras que la nueva CLI requiere ~7.5s para lo mismo sin caché ni paralelización. Con el archivo de caché habilitado y existente, la CLI actual aún necesita ~22 segundos, frente a ~1.3 segundos de la nueva CLI. Esta cifra podría reducirse a la mitad con futuras optimizaciones.
Si hay algo que recordar de esta larga publicación es que si quieres que la CLI sea lo más rápida posible, debes conservar el archivo de caché. Por defecto, el archivo de caché se almacena en ./node_modules/.cache/prettier, y su ubicación se puede personalizar con la bandera --cache-location <path>. Lo repito: si el rendimiento es importante en tu caso, la acción más significativa para acelerar el proceso es conservar el archivo de caché entre ejecuciones.
Conjeturas sobre cómo acelerar esto aún más:
-
Una oportunidad de optimización sería acelerar el cálculo de hashes en Node. Calcular los mismos hashes en Bun parece ser ~3 veces más rápido, así que seguramente hay margen de mejora. He reportado esto a Node, pero aún no se ha presentado ningún PR para solucionarlo, parece complejo.
-
Potencialmente, los archivos de configuración analizados también podrían almacenarse en caché, en lugar de solo recordar su hash, pero normalmente debería haber solo unos pocos, por lo que probablemente no marcaría mucha diferencia.
-
Potencialmente se podría eliminar o cargar de forma diferida más código, acelerando un poco más la ruta completamente cacheadada.
Formateo
Casi hemos llegado al final del flujo: sabemos qué archivos necesitamos formatear y solo tenemos que hacerlo.
No he investigado mucho la optimización de la función central de formateo, ya que para pocos archivos ya parece razonablemente rápida, y la mayor lentitud de la CLI parecía venir de resolver configuraciones de manera ineficiente y no recordar el trabajo pasado. Pero ese podría ser el próximo gran tema a investigar. Sin embargo, es posible que no haya oportunidades de optimización importantes y/o fáciles; con un perfilado rápido no detecté ninguna.
He probado un par de cosas más, eso sí.
Primero, múltiples archivos pueden formatearse en paralelo, ahora es el comportamiento predeterminado y existe una bandera --no-parallel para desactivarlo. También se puede usar la bandera --parallel-workers <int> para establecer un número personalizado de workers y ajustarlo manualmente. En mi computadora de 10 núcleos con paralelización, el tiempo necesario para verificar el monorepo de Babel baja de ~7.5s a ~5.5s, lo cual no parece particularmente impresionante. No estoy seguro de por qué no obtengo una mejor escalabilidad, me gustaría investigarlo más a fondo eventualmente. Sin embargo, hay repositorios mucho más grandes y máquinas de CI con cientos de núcleos donde la diferencia podría ser mucho mayor para tu caso de uso, además de todas las demás optimizaciones.
Finalmente probé reemplazar rápidamente la función de formato de Prettier con @wasm-fmt/biome_fmt, que es la función de formato de Biome compilada a WASM, y obtengo ~3.5s para verificar el monorepo de Babel sin paralelización y ~2.2s con paralelización. Es decir, aproximadamente el doble de rápido que con el propio formateador de Prettier. Potencialmente la mejora podría ser aún mayor si la función de formato de Biome se compilara a un módulo nativo de Node, aunque no estoy seguro.
Conjeturas sobre cómo acelerar esto aún más:
-
No he trabajado mucho en el núcleo del formateo, que parece al menos 2x más lento de lo óptimo, pero el trabajo requerido para mejorarlo podría ser significativo. Sin duda hay margen de mejora.
-
La bandera
--parallel, aunque activada por defecto, tiene un pequeño inconveniente: si tienes pocos archivos para formatear pero muchos núcleos disponibles, podrías asignar pocos archivos por núcleo, lo que en realidad puede ralentizar un poco el proceso. Probablemente esto pueda solucionarse ajustando dinámicamente el tamaño del grupo según algunas heurísticas. Actualmente está activada por defecto porque solo ralentiza en escenarios que de todos modos son rápidos, mientras proporciona una mejora significativa en situaciones que serían mucho más lentas.
Salida a la terminal
El paso final es mostrar en la terminal el resultado del comando solicitado a la CLI.
No había mucho que optimizar aquí, pero se encontraron un par de mejoras:
-
Primero, en algunos casos (como al formatear muchos archivos pequeños), la CLI actual mostraba rápidamente la ruta del archivo que estaba formateando solo para borrarla un milisegundo después. Hacer esto para miles de archivos es sorprendentemente costoso porque las llamadas
console.logson síncronas y bloquean el hilo principal. Además, si hacemos esto 100 veces en 16ms, es inútil porque nuestra pantalla quizás solo se actualizó una o dos veces en ese lapso. La nueva CLI actualmente no muestra los archivos que se están formateando, ahorrando cientos de milisegundos en algunos casos. -
Finalmente, la CLI actual puede llamar
console.logmiles de veces dependiendo de los archivos formateados, mientras que la nueva CLI agrupa los logs y realiza un soloconsole.logal final, lo que en algunos casos también puede ser notablemente más rápido.
Creo que el principal margen de mejora en esta área sería implementar algo visualmente interesante que mantenga al usuario ocupado mirándolo, ya que la percepción de rendimiento puede ser más importante que el rendimiento real, pero haciéndolo sin sobrecargar tanto la computadora.
Resultados
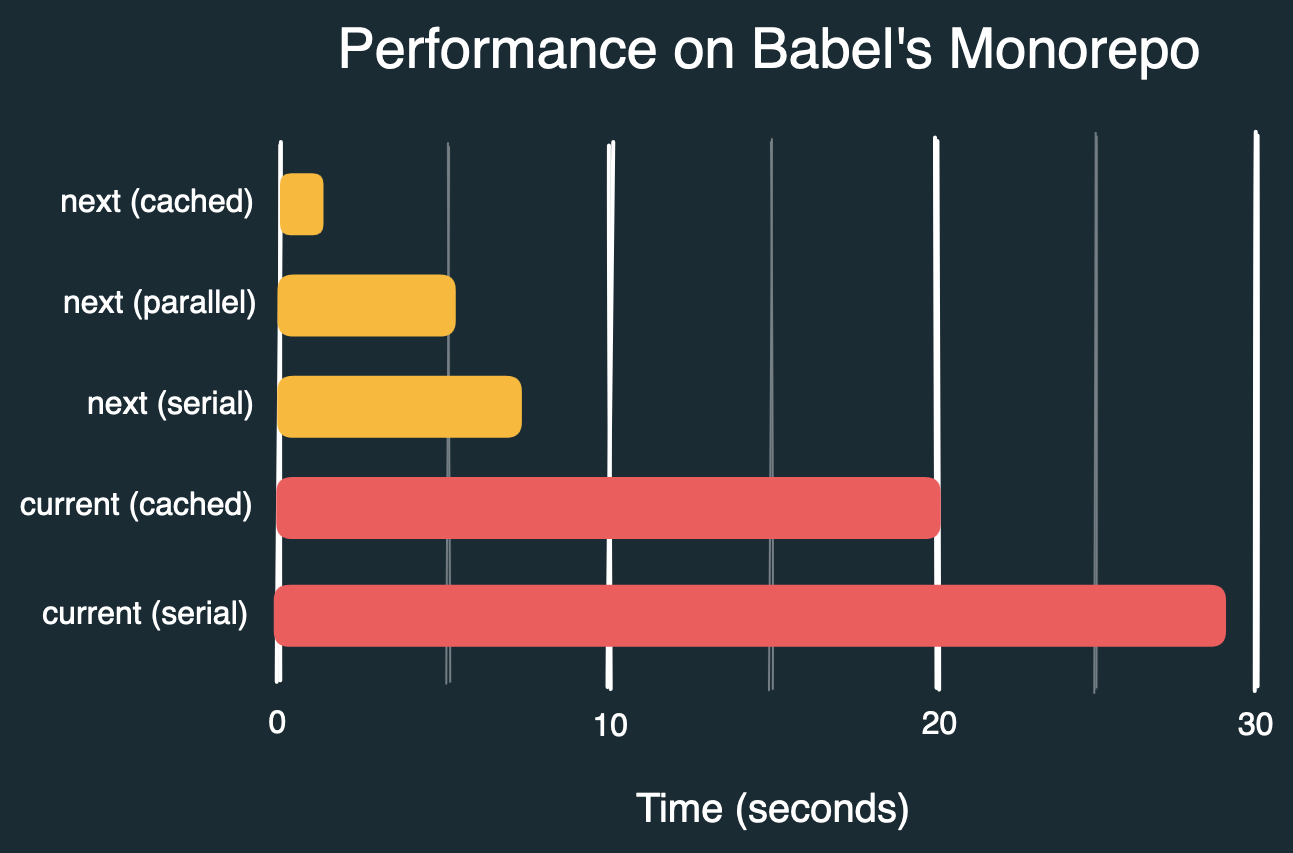
Antes de concluir, aquí hay algunos números que observo al verificar archivos en el monorepo de Babel (todos formateados pero con 9 archivos con errores), usando varias banderas y comparando la CLI actual con la nueva:
prettier packages --check # 29s
prettier packages --check --cache # 20s
prettier@next packages --check --no-cache --no-parallel # 7.3s
prettier@next packages --check --no-cache # 5.5s
prettier@next packages --check # 1.3s
Por defecto, los tiempos para el mismo comando pasan de ~29s a ~1.3s, lo que supone una aceleración de ~22x. Esto requiere que el archivo de caché se conserve entre ejecuciones. Probablemente podamos acercarnos mucho más a una aceleración de 50x en el futuro.
Si el archivo de caché no se conserva, o si desactivas explícitamente el almacenamiento en caché, o si es la primera ejecución, los tiempos pasan de ~29s a ~5.5s con paralelización (en mi equipo), lo que supone una aceleración de ~5x que sigue siendo muy significativa.
Vale la pena reiterar que esta mejora se logra sin cambiar nada en la función format de Prettier.
Resultados comparados con Biome
Es interesante comparar nuestros números con los de Biome, el formateador líder en Rust y probable campeón de rendimiento:
biome format packages
# Diagnostics not shown: 25938.
# Compared 28703 file(s) in 869ms
# Skipped 4770 file(s)
Aquí Biome está verificando el formato de ~11k archivos más que nuestra CLI, ya que aparentemente aún no implementan la resolución de .gitignore y/o .prettierignore. Puede haber otras diferencias de comportamiento significativas, no estoy seguro.
Al parchear manualmente nuestra CLI para desactivar el soporte de archivos ignore (intentando emular mejor el comportamiento de Biome), obtenemos este número:
prettier@next packages --check --no-cache # 15s
Esta comparación debe tomarse con cautela porque las herramientas no hacen exactamente lo mismo, pero es interesante ver la velocidad con que Biome verifica el formato de tantos archivos. Velocidad que probablemente necesitemos igualar usando un archivo de caché.
Diferentes enfoques para intentar acelerar masivamente la experiencia de usuario.
Conclusión
La nueva CLI sigue en desarrollo, ¡pero nos entusiasma que la pruebes! Puedes instalarla hoy mismo.
Me encantaría ver la aceleración que la nueva CLI te proporciona. Siéntete libre de tuitear tus resultados a @PrettierCode o directamente a @fabiospampinato, especialmente si tienes preguntas o ideas para acelerar aún más el proceso.