Prettiers CLI: Eine tiefgehende Leistungsanalyse

Diese Seite wurde von PageTurner AI übersetzt (Beta). Nicht offiziell vom Projekt unterstützt. Fehler gefunden? Problem melden →
Hallo, ich bin Fabio und wurde vom Prettier-Team beauftragt, die Kommandozeilenschnittstelle (CLI) von Prettier zu beschleunigen. In diesem Beitrag werfen wir einen Blick auf die Optimierungen, die ich entdeckt habe, den Prozess, der zu ihrer Entdeckung führte, beeindruckende Vergleichszahlen zwischen der aktuellen und der neuen CLI sowie mögliche nächste Optimierungsschritte.
Installation
Die neue, in Entwicklung befindliche CLI für Prettier wurde gerade veröffentlicht und kann bereits installiert werden:
npm install prettier@next
Sie sollte weitgehend abwärtskompatibel sein:
prettier . --check # Like before, but faster
Falls Probleme auftreten, kann vorübergehend die alte CLI über eine Umgebungsvariable verwendet werden:
PRETTIER_LEGACY_CLI=1 prettier . --check
Ein Test via npx ist ebenfalls möglich, wobei npx selbst relativ langsam ist:
npx prettier@next . --check
Das Ziel ist eine nahezu 100%ige Abwärtskompatibilität, bevor sie in einer zukünftigen stabilen Version des prettier-Pakets die aktuelle CLI ersetzt.
Überblick
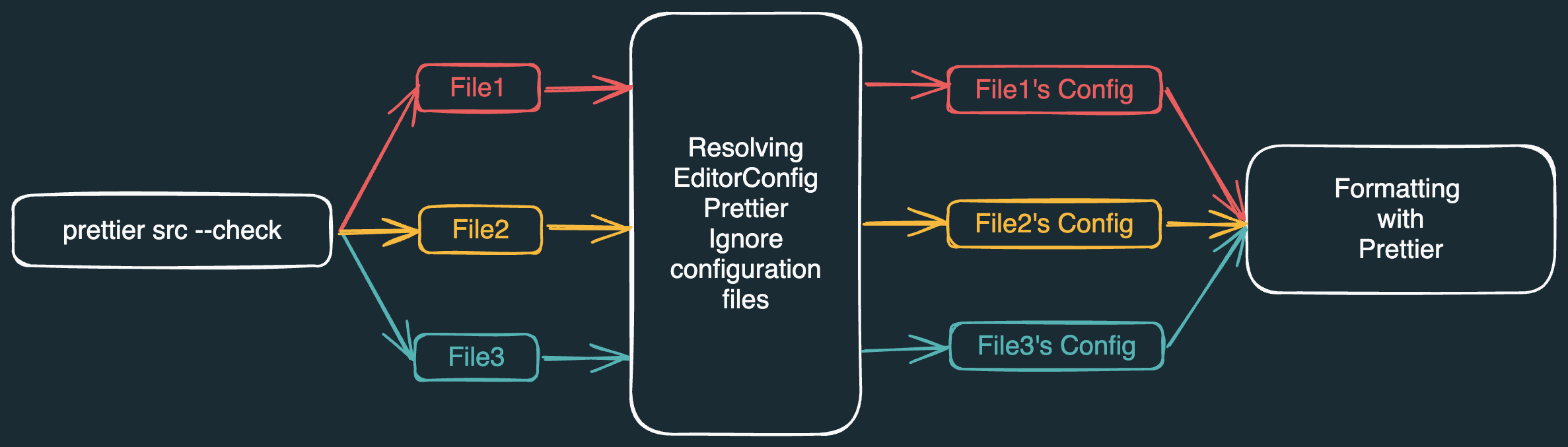
Die CLI von Prettier funktioniert grob wie im obigen Diagramm dargestellt:
-
Es gibt eine Aktion, die wir auf Dateien ausführen möchten, z.B. die Überprüfung ihrer korrekten Formatierung.
-
Wir müssen alle Dateien finden, auf die diese Aktion angewendet werden soll.
-
Wir müssen
.gitignore- und.prettierignore-Dateien auflösen, um zu bestimmen, welche Dateien ignoriert werden sollen. -
Wir müssen
.editorconfig-Dateien auflösen, um EditorConfig-spezifische Formatierungseinstellungen für diese Dateien zu erhalten. -
Wir müssen
.prettierrc-Dateien und weitere ~10 auflösen, um Prettier-spezifische Formatierungskonfigurationen zu erhalten. -
Wir müssen für jede Datei prüfen, ob sie ihrer Formatierungskonfiguration entspricht.
-
Abschließend müssen wir ein Ergebnis im Terminal ausgeben.
Nach dieser allgemeinen Betrachtung der CLI-Architektur lassen sich hauptsächlich drei Beobachtungen festhalten:
-
Der Arbeitsaufwand skaliert mit der Anzahl der Zieldateien. Da die meisten Dateien zwischen CLI-Ausführungen unverändert bleiben (z.B. werden in einem ausreichend großen Repository pro Commit nur wenige Dateien geändert), könnte der Großteil der Arbeit übersprungen werden, wenn Ergebnisse vorheriger Läufe gespeichert würden.
-
Es müssen potenziell sehr viele Konfigurationsdateien aufgelöst werden, da Repositorys Tausende von Ordnern enthalten können und jeder Ordner Konfigurationsdateien beinhalten kann. Selbst wenn nur 10 verschiedene
.editorconfig-Dateien gefunden werden, müssen diese mit ihren Glob-Mustern für jede Zieldatei kombiniert werden. Allerdings enthalten die meisten Repositorys nur eine Handvoll.editorconfig-Dateien – selbst bei Tausenden von Ordnern – was diesen Schritt weniger aufwändig machen sollte. -
Wenn ein Programm ausschließlich notwendige Aufgaben effizient ausführt, arbeitet es zwangsläufig effizient. Daher konzentrieren wir uns darauf, unnötige Arbeit zu vermeiden und unvermeidbare Aufgaben zu optimieren.
Basierend auf diesen Beobachtungen habe ich eine neue Prettier-CLI von Grund auf entwickelt, da Neuimplementierungen mit Fokus auf Leistung oft einfacher sind als nachträgliche Optimierungen.
Für Messungen in diesem Beitrag verwende ich das Babel-Monorepo, da es als aussagekräftiger Benchmark dient und praktische Leistungsverbesserungen für ein reales, großes Monorepo verdeutlicht.
Schnelles Auffinden von Dateien
Zunächst müssen wir unsere Zieldateien finden. Die aktuelle Prettier-CLI verwendet dafür fast-glob. Der entsprechende Code sieht etwa so aus:
import fastGlob from "fast-glob";
const files = await fastGlob("packages/**/*.{js,cjs,mjs}", {
ignore: ["**/.git", "**/.sl", "**/.svn", "**/.hg", "**/node_modules"],
absolute: true,
dot: true,
followSymbolicLinks: false,
onlyFiles: true,
unique: true,
});
Bei Ausführung im Babel-Monorepo benötigt dies ~220ms, um ~17k Dateien (von ~30k Gesamtdateien) zu finden – ein akzeptables Ergebnis angesichts von über 13k Ordnern.
Ein schnelles Profiling zeigt, dass viel Zeit für das Ignorieren von Dateien via Glob-Mustern aufgewendet wird, die intern in Regexes umgewandelt und einzeln abgeglichen werden. Der Versuch, Globs zu einem einzigen Muster "**/{.git,.sl,.svn,.hg,node_modules}" zusammenzufassen, scheiterte, da sie intern wieder aufgeteilt wurden.
Durch vollständiges Deaktivieren der Ignore-Globs werden nahezu identische Dateien in ~180ms gefunden – eine Zeitersparnis von ~20%. Eine effizientere Glob-Verarbeitung könnte die Leistung also weiter verbessern.
Hier ist erwähnenswert, dass fast-glob eine clevere Optimierung vornimmt: Bei einem Glob wie packages/**/*.{js,cjs,mjs} erkennt es den statischen Anfangspfad. Was wir tatsächlich von ihm verlangen, ist nach **/*.{js,cjs.mjs} im Ordner packages zu suchen. Dies ist besonders effizient, wenn viele irrelevante Dateien in anderen Ordnern existieren.
Diese Logik brachte mich auf eine Idee: Ignore-Globs haben statische Teile am Ende, nicht am Anfang. Daher entwickelte ich eine alternative Bibliothek für Globs mit statischen Enden. Der entsprechende Code:
import readdir from "tiny-readdir-glob";
const { files } = await readdir("packages/**/*.{js,cjs,mjs}", {
ignore: "**/{.git,.sl,.svn,.hg,node_modules}",
followSymlinks: false,
});
Diese Lösung findet dieselben Dateien in nur ~130ms. Selbst das Deaktivieren der Ignore-Globs zeigt kaum messbaren Overhead – die Optimierung ist hier so effizient, dass ihr Einfluss minimal ist.
Die Geschwindigkeitssteigerung erklärt sich durch mehrere Faktoren:
-
Neben den Ignore-Globs wurde auch der
**/*.{js,cjs,mjs}-Teil des Hauptglobs optimiert. -
Glob-Abgleiche erfolgen normalerweise gegen relative Pfade einer Datei vom Stammordner aus, was
path.relative-Aufrufe erfordern würde. Bei einem Glob wie**/.gitist dieser Schritt jedoch entbehrlich, da ohnehin nur das Dateiende relevant ist – daher habe ich diesepath.relative-Aufrufe komplett entfernt. -
Beide Bibliotheken verwenden Node.js
fs.readdir, das Datei- und Ordnernamen (nicht absolute Pfade) zurückgibt. Durch manuelles Zusammenfügen mit dem Pfadtrennzeichen stattpath.joinwird zusätzliche Performance gewonnen.
Darüber hinaus ist diese neue Bibliothek etwa 90 % kleiner – rund 65 KB minifizierter Code werden nicht mehr benötigt, was den Start der gesamten CLI beschleunigt. In deutlich kleineren Repositories als dem von Babel kann die neue CLI bereits alle Zieldateien gefunden haben, während die alte gerade erst mit dem Parsen von fast-glob fertig geworden wäre.
Das Umschreiben dieses Teils der CLI mag für den erzielten Geschwindigkeitsgewinn übertrieben erscheinen, aber der Hauptgrund dafür ist ein anderer. Es wirkt, als könnten wir hier nichts tun, was die CLI um mehrere Sekunden beschleunigt, da das Finden aller Dateien zunächst weniger als eine halbe Sekunde dauert. Der entscheidende Punkt ist jedoch: Für die gesamte CLI müssen wir nicht nur Dateien zum Formatieren finden, sondern auch Konfigurationsdateien. Die Information über jede einzelne gefundene Datei und jeden Ordner – selbst wenn sie nicht unseren Globs entsprechen – ist äußerst wertvoll, um später Sekunden einzusparen. tiny-readdir-glob liefert diese Information quasi kostenlos, daher erschien die Entwicklung allein dafür bereits lohnenswert.
Die wesentlichen Erkenntnisse dieses Abschnitts zusammengefasst:
-
Geben Sie Prettier nach Möglichkeit immer die zu suchenden Dateiendungen an, z.B. mit einem Glob wie
packages/**/*.{js,cjs,mjs}. Würden Sie stattdessenpackages/**/*oder nurpackagesverwenden, müssten in diesem Szenario 13.000 zusätzliche Dateien verarbeitet werden, was für Prettier später aufwändiger zu verwerfen wäre. -
Selbst in optimierten Bibliotheken bleibt immer Raum für Leistungsoptimierungen oder Spezialfälle – wenn man die Zeit investiert.
-
Es lohnt sich zu überlegen, welche Informationen verworfen werden oder deren Rekonstruktion aufwändig ist. Hier muss die Glob-Bibliothek Dateien/Ordner kennen – macht man diese dem Aufrufer zugänglich, erschließt sich zusätzliche Performance quasi kostenlos.
Vermutungen zur weiteren Beschleunigung:
- Der Flaschenhals scheint bei
fs.promises.readdirin Node bzw. dem Overhead durch Promises pro Ordner zu liegen. Es könnte sich lohnen, die Callback-Version dieser API zu nutzen oder Optimierungsmöglichkeiten in Node selbst zu prüfen.
Konfigurationen schnell auflösen
Dies ist wahrscheinlich die wirkungsvollste Optimierung der neuen CLI. Im Kern geht es darum, Konfigurationsdateien maximal schnell zu finden: Jeder Ordner wird nur einmal auf Konfigurationsdateien geprüft, und gefundene Konfigurationen werden nur einmal geparst.
Ein Hauptproblem der aktuellen CLI ist die Zwischenspeicherung aufgelöster Konfigurationen nach Dateipfad statt Ordnerpfad. Beispiel: Babels Monorepo hat ~17.000 zu formatierende Dateien, aber nur eine .editorconfig-Datei im gesamten Repo. Eigentlich sollte diese Datei einmal geparst werden – stattdessen geschah dies ~17.000 Mal. Stellen Sie sich vor, diese ~17.000 Dateien lägen im selben Ordner: Dieser Ordner wurde ~17.000 Mal gefragt, ob er eine .editorconfig-Datei enthält. Je tieber Dateien in Ordnern verschachtelt waren, desto langsamer wurde die gesamte CLI.
Dieses Problem wurde weitgehend in zwei Schritten gelöst:
-
Aufgelöste Konfigurationsdateien werden jetzt nach Ordnerpfad zwischengespeichert – unabhängig von Dateianzahl oder Verschachtelungstiefe.
-
Gefundene Ordner werden nun quasi 0 Mal auf jede der ~15 unterstützten Konfigurationsdateien geprüft, denn wir kennen aus dem vorherigen Abschnitt jede Datei im Repo. Ein einfacher Lookup ist deutlich schneller als Filesystem-Abfragen. In kleinen Repos wäre dies vernachlässigbar, aber bei Babel mit ~13.000 Ordnern summieren sich 13.000 * 15 Filesystem-Checks
addiertmultipliziert schnell.
Betrachten wir nun die Auflösung jedes Konfigurationstyps im Detail:
EditorConfig-Konfigurationen auflösen
Gehen wir davon aus, dass wir im vorherigen Schritt alle .editorconfig-Dateien im Repository geparst haben und für jede Zieldatei die relevanten Konfigurationen in konstanter Zeit abrufen können. Unser Ziel ist es nun, diese für jede Zieldatei in ein einziges Konfigurationsobjekt zusammenzuführen.
Diese Idee lässt sich jedoch nicht direkt umsetzen, da das editorconfig-Paket keine entsprechende Funktion bietet. Die ähnlichste Funktion parseFromFiles ist veraltet und würde Konfigurationen als Strings erwarten – sie würde diese also bei jedem Aufruf neu parsen, genau das, was wir ursprünglich vermeiden wollten. Wir möchten diese Dateien nur einmal parsen.
Daher wurde das Paket für Prettiers Anforderungen neu implementiert: tiny-editorconfig bietet genau die benötigte resolve-Funktion und überlässt uns die Logik zur Konfigurationssuche. Dies entspricht unseren Anforderungen, da wir diese Dateien auf spezielle Weise cachen müssen.
Zusätzlich habe ich den zugrundeliegenden INI-Parser neu geschrieben, der nun etwa 9x schneller ist. Obwohl dies bei den meisten Repositories (mit nur einer .editorconfig-Datei) kaum ins Gewicht fällt, macht mir das Schreiben solcher Parser Spaß – und falls Ihr Repository tausende .editorconfig-Dateien enthält, werden Sie den Geschwindigkeitszuwachs bemerken!
Die neue Bibliothek ist zudem ~82% kleiner: ~50 KB minifizierter Code wurden entfernt, was den CLI-Start beschleunigt. Sie verwendet dieselbe Glob-Bibliothek wie tiny-readdir-glob, während die aktuelle CLI unterschiedliche Bibliotheken (fast-glob und editorconfig) nutzt – effektiv wurde also noch mehr Code entfernt.
Für Babels Monorepo reduzierte sich die Verarbeitungszeit von mehreren Sekunden auf etwa ~100 ms.
Vermutungen zur weiteren Beschleunigung:
- In vielen Fällen könnte man Konfigurationen für alle möglichen Dateipfade vorab berechnen. Abhängig von den Globs könnten maximal drei Konfigurationsvarianten entstehen: für nicht-matchende Dateien, für
**/*.jsund für**/*.md. Die Implementierung ist komplex und der praktische Nutzen unklar, aber ein interessanter Ansatz für die Zukunft.
Auflösen von Prettier-Konfigurationen
Für Prettier-spezifische Konfigurationen (wie .prettierrc) gehen wir ebenfalls davon aus, dass alle Dateien aufgelöst sind und in konstanter Zeit abrufbar sind.
Die Situation ist identisch zu EditorConfig, daher verwenden wir denselben Ansatz. Die Mergelogik wird direkt in die CLI integriert, da ein separates Paket hierfür kaum Mehrwert bieten würde.
Wesentliche Aspekte für zukünftige Optimierungen:
-
Die Vielzahl unterschiedlicher Konfigurationsdateien führt bei Babels Monorepo zu ~150k Lookups im Pfadobjekt – nicht extrem teuer, aber optimierbar. Weniger Formate würden die Verarbeitung beschleunigen.
-
Einige Parser (z.B.
json5) sind ineffizient: Er benötigt ~100x mehr Code als der kleinste JSONC-Parser und ist bis zu 50x langsamer. Weniger unterstützte Formate würden die CLI schlanker machen. -
Wenn wir nur einmal prüfen könnten, ob beispielsweise eine Datei namens
.prettierrc.json5irgendwo im Repository gefunden wurde, könnten wir die Anzahl der Prüfungen für diese Konfigurationsdateien um eine Größenordnung reduzieren. Denn wenn nirgendwo im Repo eine Datei mit diesem Namen gefunden wurde, müssen wir nicht jedes der ~13.000 Verzeichnisse von Babel danach fragen. Die Liste aller bekannten Dateinamen ist ein weiterer wertvoller Informationssatz, den uns die verwendete Glob-Bibliothek kostenlos liefern könnte.
Ignore-Konfigurationen auflösen
Zuletzt müssen wir .gitignore- und .prettierignore-Dateien verarbeiten, um zu verstehen, welche gefundenen Dateien ignoriert werden sollen. Wir gehen davon aus, dass wir bereits alle gefundenen Ignore-Dateien aufgelöst haben und für jede Zieldatei in konstanter Zeit darauf zugreifen können.
Ich implementiere hier keine größeren Optimierungen, sondern lasse größtenteils node-ignore eine Funktion generieren, die wir aufrufen können, um zu prüfen, ob eine Datei ignoriert werden soll.
Eine kleine Optimierung ist jedoch, den Aufruf von path.relative und in manchen Fällen auch der ignore-Funktion zu überspringen. Ignore-Dateien matchen grob den relativen Pfad der gefundenen Dateien vom Verzeichnis aus, in dem die Ignore-Datei liegt. Da wir wissen, dass alle Pfade normalisiert sind: Wenn der absolute Pfad einer Zieldatei nicht mit dem absoluten Pfad des Verzeichnisses beginnt, in dem eine Ignore-Datei existierte, liegt diese Datei außerhalb des verwalteten Bereichs – wir müssen die ignore-Funktion, die uns node-ignore bereitgestellt hat, nicht aufrufen.
Ein beträchtlicher Teil der Zeit wird jedoch für das Matching der Globs in diesen Dateien gegen die gefundenen Dateien aufgewendet – Hunderte Millisekunden bei Tausenden Dateien. Denn es kann einfach viele Globs in diesen Dateien und viele zu matchende Dateien geben, was im Worst-Case grob die Anzahl der versuchten Glob-Matches ergibt.
Das Gute an .gitignore- und .prettierignore-Dateien ist jedoch, dass sie sich oft selbst amortisieren: Die Zeit für das Parsen und Dateimatching ist meist geringer als die Verarbeitung jeder Datei, die sonst durch sie verworfen worden wäre.
Vermutungen zur weiteren Beschleunigung:
-
Vielleicht könnten die meisten dieser Globs zu einem einzigen komplexeren Glob zusammengeführt und gemeinsam in einem Durchgang vom Engine gematcht werden, da uns nicht interessiert, welcher exakte Glob matchte, sondern nur ob irgendeiner matchte.
-
Vielleicht könnten Globs in anderer Reihenfolge ausgeführt werden – wenn einfachere und weiter gefasste Globs zuerst laufen, könnte das die durchschnittliche Matching-Zeit verringern. Dies würde jedoch keinen Unterschied machen, wenn die meisten gefundenen Dateien nicht ignoriert werden.
-
Vielleicht könnten wir einfach mit einem Cache merken, welche Dateipfade gematcht haben – aber es scheint, dass sich dies auch stark ohne Caching beschleunigen ließe.
Caching
An diesem Punkt haben wir alle Dateien gefunden und alle Konfigurationen geparst. Was bleibt, ist die potenziell aufwändige Arbeit, jede Zieldatei zu formatieren – und hier kommt Caching ins Spiel.
Die aktuelle CLI unterstützt zwar Caching, aber nur optional via explizitem --cache-Flag. Sie merkt sich nicht, ob eine Datei im vorherigen Lauf als nicht korrekt formatiert befunden wurde, sondern nur wenn sie korrekt formatiert war. Das kann in manchen Fällen unnötigen Overhead verursachen, da diese unformatierten Dateien erneut formatiert werden, um ihren Status zu prüfen – obwohl wir uns vom letzten Lauf gemerkt hätten, dass sie nicht korrekt sind.
Unser Ziel ist es, möglichst viel Arbeit zu überspringen, indem wir uns merken, ob eine Datei formatiert war oder nicht – bei gleichzeitig möglichst kleinen Cache-Dateien und ohne viel Mehraufwand durch den Caching-Mechanismus selbst.
Die neue CLI verwendet standardmäßig ein Opt-Out-Caching, d.h. das Caching ist immer aktiviert, es sei denn, Sie deaktivieren es explizit mit dem Flag --no-cache. Dadurch profitieren standardmäßig deutlich mehr Nutzer von den Vorteilen. Das Caching ist jetzt standardmäßig aktiviert, weil es alle Faktoren berücksichtigt – es sollte daher unrealistisch sein, dass der Cache der CLI falsche Informationen liefert. Bei Änderungen folgender Elemente wird der Cache (oder Teile davon) automatisch ungültig: Prettier-Version, alle aufgelösten EditorConfig/Prettier/Ignore-Konfigurationsdateien und ihre Pfade, über CLI-Flags bereitgestellte Formatierungsoptionen, der tatsächliche Inhalt jeder Datei sowie der Dateipfad jeder Datei.
Der Haupttrick besteht darin, dass der Cache für jede Datei nicht direkt von ihrer aufgelösten Formatierungskonfiguration abhängen soll. Andernfalls müssten wir diese Konfigurationsdateien für jede Zieldatei zusammenführen, das resultierende Objekt serialisieren und hashen – was teurer wäre als gewünscht.
Stattdessen parst die neue CLI alle gefundenen Konfigurationsdateien, serialisiert und hasht sie. Dies benötigt eine konstante Zeit – unabhängig von der Anzahl später zu formatierender Dateien – und erfordert nur einen einzigen Hash im Cache, der indirekt für Konfigurationsdateien steht. Dies ist sicher, denn wenn Pfade und Inhalte der Konfigurationsdateien unverändert bleiben, wird jede Datei mit identischem Pfad wie im vorherigen Durchlauf zwangsläufig mit derselben aufgelösten Formatierungskonfiguration verarbeitet. Einziges Risiko: Fehler in Abhängigkeiten beim Parsen. Im Worst Case kann Prettiers Version zusammen mit der fehlerhaften Dependency aktualisiert werden.
Zahlenbeispiel: Die aktuelle CLI prüft Babels Monorepo ohne Cache in ~29 Sekunden, die neue CLI benötigt ohne Cache und ohne Parallelisierung ~7,5s. Mit aktiviertem Cache benötigt die aktuelle CLI noch ~22 Sekunden, während die neue CLI nur ~1,3s braucht – diese Zahl könnte durch weitere Optimierungen wahrscheinlich halbiert werden.
Die wichtigste Erkenntnis dieses Beitrags: Für maximale CLI-Geschwindigkeit müssen Sie den Cache beibehalten. Die Cache-Datei liegt standardmäßig unter ./node_modules/.cache/prettier, ihr Speicherort ist via --cache-location <path> anpassbar. Ich betone: Wenn Performance entscheidend ist, ist das Beibehalten des Caches zwischen Durchläufen die wirkungsvollste Beschleunigungsmaßnahme.
Vermutungen zur weiteren Beschleunigung:
-
Optimierungspotenzial beim Hashing in Node: Dieselben Hashes sind in Bun ~3x schneller. Dazu habe ich berichtet – noch kein PR, scheint komplex.
-
Eventuell könnten geparste Konfigurationsdateien selbst gecached werden (nicht nur ihr Hash). Da meist nur wenige existieren, wäre der Effekt aber gering.
-
Weitere Code-Reduktion oder Lazy-Loading könnte den vollständig gecachten Pfad zusätzlich beschleunigen.
Formatierung
Wir erreichen nun fast das Pipeline-Ende: Die zu formatierenden Dateien sind identifiziert, nun geht's ans Ausführen.
Die Kernformatierungsfunktion selbst habe ich kaum optimiert – bei wenigen Dateien ist sie bereits schnell genug. Die Hauptverlangsamung lag im ineffizienten Konfigurationsauflösen und fehlendem Caching früherer Arbeiten. Nächster Fokus: Eventuelle Optimierungen dort scheinen jedoch nicht offensichtlich; schnelles Profiling zeigte keine Low-Hanging-Fruits.
Einige andere Ansätze habe ich dennoch getestet.
Zunächst können mehrere Dateien parallel formatiert werden – das ist jetzt die Standardeinstellung, wobei die Option --no-parallel verfügbar ist, um dies zu deaktivieren. Das Flag --parallel-workers <int> ermöglicht zudem die manuelle Feinabstimmung der Anzahl verwendeter Worker. Auf meinem 10-Kern-Rechner reduziert sich die Prüfzeit für Babels Monorepo durch Parallelisierung von ~7,5s auf ~5,5s. Dies erscheint nicht besonders beeindruckend; ich bin unsicher, warum die Skalierung nicht besser ausfällt und möchte dem später nachgehen. Bei größeren Repositories und CI-Systemen mit Hunderten von Kernen könnte der Unterschied jedoch erheblicher sein – zusätzlich zu allen anderen Optimierungen.
Abschließend testete ich kurz den Ersatz von Prettiers Formatierungsfunktion durch @wasm-fmt/biome_fmt – die zu WASM kompilierte Formatierungsfunktion von Biome. Dabei zeigten sich ~3,5s für die Prüfung von Babels Monorepo ohne Parallelisierung und ~2,2s mit Parallelisierung. Das sind etwa doppelt so gute Werte wie mit Prettiers eigenem Formatter. Möglicherweise wäre der Gewinn noch größer, wenn Biomes Funktion als natives Node-Modul kompiliert würde.
Vermutungen zur weiteren Beschleunigung:
-
Die Kernformatierung wurde kaum optimiert und scheint mindestens doppelt so langsam wie optimal zu sein. Die dafür nötigen Anpassungen könnten umfangreich sein – hier besteht definitiv Verbesserungspotenzial.
-
Das standardmäßig aktive
--parallel-Flag hat eine kleine Schwäche: Bei wenigen zu formatierenden Dateien mit vielen verfügbaren Kernen könnte die geringe Dateianzahl pro Kern die Geschwindigkeit leicht reduzieren. Dies ließe sich wahrscheinlich durch heuristische Poolgrößenanpassung lösen. Es bleibt standardaktiviert, weil es nur in ohnehin schnellen Szenarien minimal bremst, während es in langsamen Fällen erhebliche Verbesserungen bringt.
Ausgabe im Terminal
Der letzte Schritt ist die Ausgabe des Befehlsergebnisses im Terminal.
Hier gab es wenig Optimierungsbedarf, aber zwei Ansätze:
-
Die aktuelle CLI gibt bei vielen kleinen Dateien schnell den aktuellen Dateipfad aus, löscht ihn aber sofort nach der Formatierung. Bei Tausenden Dateien wird dies überraschend ressourcenintensiv, da
console.log-Aufrufe synchron sind und den Hauptthread blockieren. Zudem sind bei 100 Aufrufen in 16ms die meisten Ausgaben unsichtbar, da der Bildschirm nur 1-2x aktualisiert wird. Die neue CLI protokolliert aktuell formatierte Dateien nicht – was in manchen Fällen Hunderte Millisekunden spart. -
Die aktuelle CLI ruft
console.logtausendfach auf, abhängig davon wie viele Dateien formatiert werden, während die neue CLI Ausgaben bündelt und nur einmalig am Ende einenconsole.logausgibt – was in manchen Fällen ebenfalls überraschend schneller sein kann.
Hauptoptimierungspotenzial sehe ich in visuell ansprechenden Darstellungen, die Nutzer:innen beschäftigen (wahrgenommene Performance ist oft wichtiger als reale), ohne dabei Systemressourcen zu binden.
Ergebnisse
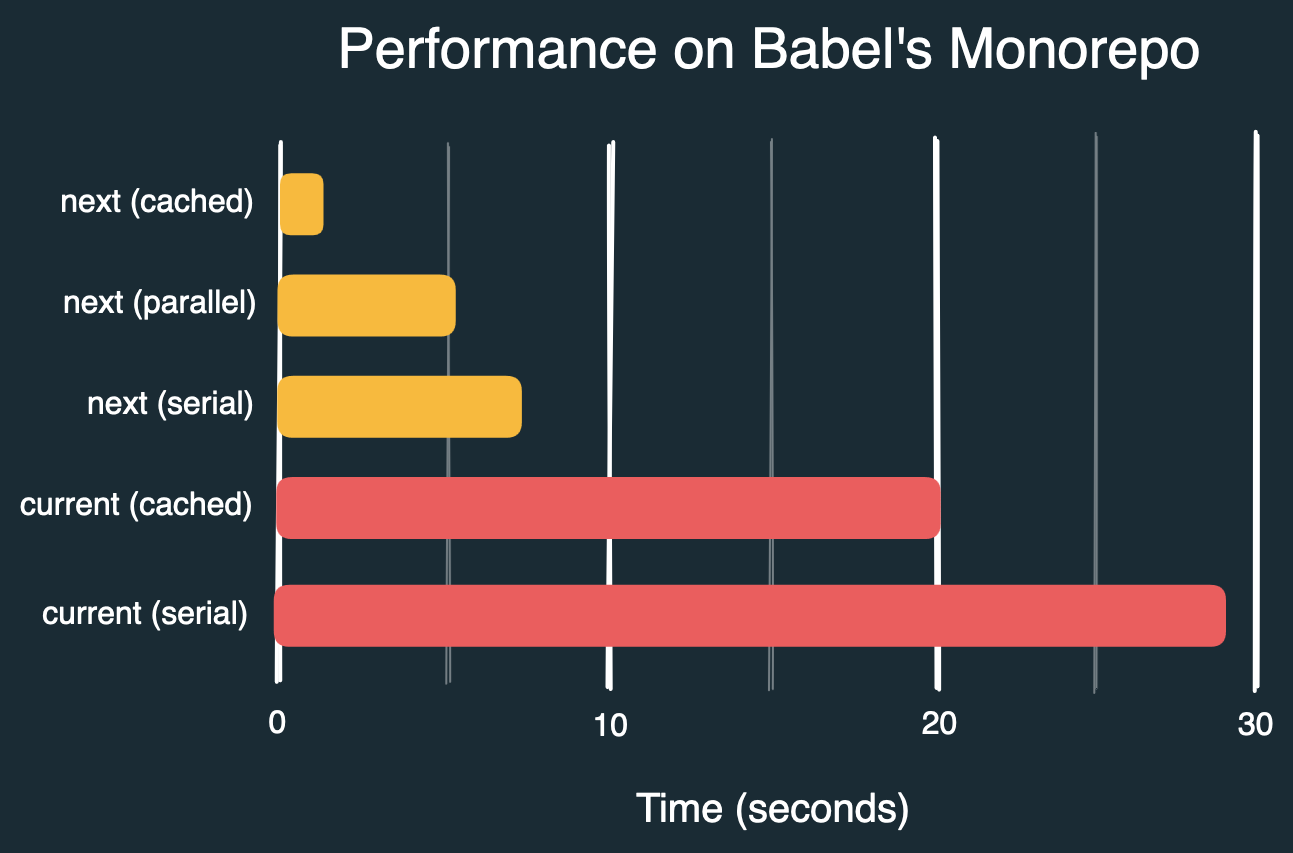
Abschließend Messwerte für die Prüfung von Babels Monorepo mit formatierten Dateien (9 fehlerhafte), verschiedenen Flags sowie aktueller und neuer CLI:
prettier packages --check # 29s
prettier packages --check --cache # 20s
prettier@next packages --check --no-cache --no-parallel # 7.3s
prettier@next packages --check --no-cache # 5.5s
prettier@next packages --check # 1.3s
Standardmäßig verkürzen sich die Ausführungszeiten für denselben Befehl von ~29s auf ~1,3s – eine Beschleunigung um das ~22-fache. Dies setzt voraus, dass die Cache-Datei zwischen den Ausführungen erhalten bleibt. Wahrscheinlich können wir in Zukunft sogar eine ~50-fache Beschleunigung erreichen.
Falls die Cache-Datei nicht erhalten bleibt, Sie Caching explizit deaktivieren oder es sich um den ersten Durchlauf handelt, reduziert sich die Zeit bei paralleler Verarbeitung auf meinem Rechner von ~29s auf ~5,5s – eine immer noch signifikante ~5-fache Beschleunigung.
Erwähnenswert ist erneut, dass diese Verbesserung ohne Änderungen an Prettiers eigentlicher format-Funktion erreicht wurde.
Ergebnisse im Vergleich zu Biome
Interessant ist der Vergleich unserer Zahlen mit denen von Biome, dem führenden Rust-Formatter und wahrscheinlichen Performance-Champion:
biome format packages
# Diagnostics not shown: 25938.
# Compared 28703 file(s) in 869ms
# Skipped 4770 file(s)
Hier prüft Biome die Formatierung von ~11.000 mehr Dateien als unsere CLI, da sie anscheinend die Auflösung von .gitignore und/oder .prettierignore noch nicht implementiert haben. Möglicherweise gibt es weitere, signifikante Verhaltensunterschiede, da bin ich mir nicht sicher.
Durch manuelles Anpassen unserer CLI zur Deaktivierung der Ignore-Datei-Unterstützung – um Biomes Verhalten näherzukommen – erhalten wir folgendes Ergebnis:
prettier@next packages --check --no-cache # 15s
Dieser Vergleich ist mit Vorsicht zu genießen, da die Tools nicht exakt dasselbe tun. Dennoch ist Biomes Geschwindigkeit bei der Formatprüfung vieler Dateien beeindruckend. Um hier mithalten zu können, benötigen wir wahrscheinlich eine Cache-Datei.
Verschiedene Ansätze, um für Nutzer massive Geschwindigkeitssteigerungen zu erreichen.
Zusammenfassung
Die neue CLI befindet sich noch in der Entwicklung, aber wir freuen uns, wenn Sie sie testen! Sie können sie bereits heute installieren.
Ich wäre interessiert an den Geschwindigkeitsverbesserungen, die die neue CLI für Sie bringt. Tweeten Sie Ihre Ergebnisse gerne an @PrettierCode oder direkt an @fabiospampinato, insbesondere wenn Sie Fragen oder Ideen zur weiteren Optimierung haben.